Datos univariados y su distribución
Felipe González
Cuantiles de un conjunto de datos
Los cuartos, octavos, etc. son útiles, fáciles de comprender y de calcular a mano (para conjuntos chicos de datos), sin embargo, necesitamos generalizar estos métodos para estudiar con más detalle la distribución de un conjunto de datos.
Como primera definición tenemos:
El cuantil \(f\) de un conjunto de datos es el valor \(q(f)\) en la escala de medición del conjunto tal que aproximadamente una fracción \(f\) de los datos son menores o iguales a \(f\).
Por ejemplo, si los datos son \(1,2,2,5,\) entonces \(1\) es el cuantil \(1/4\), \(2\) es el cuantil \(1/2\) y también el \(3/4\), y \(5\) es el cuantil \(1\).
Tenemos que resolver varios problemas con esta definición:
¿Cuál es el cuantil \(1/3\) en los datos anteriores?
Asimetría: el dato más chico es el cuantil \(1/n\), donde \(n\) es el tamaño del conjunto de datos, pero el más grande es el cuantil \(1\) (en lugar del cuantil \(1-1/n\), si la definición fuera simétrica).
Problemas adicionales surgen cuando queremos comparar los cuantiles de un conjunto de datos con los cuantiles teóricos de una distribución dada, esto para contestar preguntas como: ¿la distribución de datos es similar a una normal? Para comprender mejor los cuantiles y poder responder estas preguntas comencemos con la construcción de gráficas de cuantiles para densidades de probabilidad.
Gráficas de cuantiles teóricos
Supongamos que \(G\) es la función de distribución de una variable aleatoria continua, tal que \(G\) es diferenciable y tiene derivada positiva (por ejemplo, si la variable aleatoria tiene densidad positiva y continua en todos los reales). Entonces podemos construir la función \(q:(0,1) \to (\infty, \infty)\) dada por: \[q(f)=G^{-1}(f)\] para cualquier \(f \in (0,1)\). Decimos que \(q\) es la función de cuantiles de la variable aleatoria con distribución \(G\). Bajo esta definición, es claro que si \(X\) tiene distribución \(G\), entonces \(P(X<q(f))=G(q(f))=f\).
Ejemplo: normal
Abajo vemos cómo se ve la gráfica de cuantiles de una variable aleatoria normal estándar. A esta función la denotamos como \(q_{0,1}(f)\), y en general, a la función de cuantiles de una distribución \(Normal(\mu, \sigma^2)\) la denotamos \(q_{\mu, \sigma}(f)\).
curve(qnorm, from = 0, to=1, n = 1000, xlab='Cuantil (f)', ylab='q')
Notemos que \(q_{\mu, \sigma}(f) \to \infty\) cunado \(f \to 1\), y el cuantil \(1\) no esta definido. Análogamente el cuantil \(0\) tampoco está definido.
- ¿Cómo se ve la gráfica de cuantiles de una variable aleatoria uniforme?
- Similar al caso normal (una curva).
- Como una recta horizontal.
- Como una recta vertical.
- Como una diagonal.
Gráficas de cuantiles para un conjunto de datos
Hay varias maneras razonables de definir los cuantiles de un conjunto de datos, (ver Hyndman y Fan 1996 para una resumen de lo que usan los paquetes estadísticos). Nosotros adoptamos la siguiente construcción:
Ejemplo. Consideremos el conjunto de datos \(4,1,7,3,3,6,10\). Calcular \(f_1,f_2,...,f_7\) según la definición de arriba.
- ¿Cuál es el cuantil \(0.40\) para el ejemplo de arriba?
- 3
- 3.3
- 3.6
- 4
Acerca de nuestra definición de cuantiles. Un argumento posible para justificar la definición de arriba es (Cleveland, 1994): supongamos que \(x_i\) es resultado de redondeo, y los datos \(x_1,...,x_n\) son distintos. Cuando contamos cuántas observaciones son menores o iguales a \(x_i\), es igualmente probable que la observación real correspondiente está por arriba o por debajo de la medida \(x_i\). En el primer caso, \(x_i\) está por arriba de \((i-1)/n\) observaciones reales. En el segundo caso, \(x_i\) está por arriba de \(f\le i/n\) observaciones reales. Promediamos estos dos valores para obtener nuestra definición.
Otro argumento en favor de nuestra elección es la simetría en los valores \(f\) de los cuantiles: el dato más grande es el cuantil \(1-0.5/n\) que es complemento de \(0.5/n\), que corresponde al cuantil del mínimo.
Finalmente, notamos que bajo nuestra definición no hay cuantiles \(0\) ni \(1\). Esto es deseable cuando queremos comparar con densidades cuyos cuantiles teóricos \(0\) y \(1\) no están definidos.
Podemos hacer gráficas de la función de cuantiles de manera fácil. Estas gráficas se hacen, aproximadamente, como sigue: se ordenan los datos del más chico al más grande, se enumeran como índice, y graficamos los pares resultantes con el índice en el eje horizontal.
library(ggplot2)
library(reshape2) # aquí están los datos de propinas
n <- length(tips$total_bill)
tips$probs <- (1:n - 0.5) / n
tips$cuantiles <- quantile(tips$total_bill, probs = tips$probs, type = 5)
ggplot(tips, aes(x=probs, y = cuantiles)) +
xlab('Cuantil (f)') +
ylab('Dólares') +
geom_point()
¿Qué buscar en una gráfica de cuantiles?
Las gráficas de cuantiles son conceptualmente simples; sin embargo, su interpretación efectiva requiere práctica. Algunas guías son:
Podemos leer fácilmente la mediana y los cuartos.
Regiones en la escala de medición de los datos (dimensión vertical) con densidades de datos más altas se ven como pendientes bajas en la gráfica. Mientras que pendientes altas indican densidades de datos relativamente más bajas.
Una mayor pendiente en la forma general de la gráfica (por ejemplo, en la recta que une los cuartos) indica dispersiones más grandes.
Si el conjunto de datos se distribuye aproximadamente uniforme, entonces la gráfica debe parecerse a una recta (diagonal).
De manera más general: en las regiones donde el histograma crece conforme aumentan los valores en el conjunto de datos, la pendiente de la gráfica de cuantiles es decreciente (así que la gráfica de cuantiles es cóncava hacia abajo). Cuando el histograma decrece conforme aumentan los valores en el conjunto de datos, la pendiente de la gráfica de cuantiles es creciente (así que observamos concavidad hacia arriba).
Si la distribución tiene más dispersión hacia la derecha, la figura general de la gráfica es cóncava hacia arriba. Si tiene más dispersión a la izquierda, es cóncava hacia abajo.
¿Cómo se ve una distribución que parece tener grupos definidos donde se acumulan los datos?
Comparación de conjuntos de datos
Las gráficas de cuantiles son muy eficientes para capturar diversos aspectos en la comparación de dos o más distribuciones.
Ejemplo: estaturas. Consideramos las estaturas de un grupo de cantantes, clasificados según sus tesituras. Las gráficas de cuantiles de estos datos son como sigue:
library(lattice)
library(dplyr)
head(singer) height voice.part
1 64 Soprano 1
2 62 Soprano 1
3 66 Soprano 1
4 65 Soprano 1
5 60 Soprano 1
6 61 Soprano 1# calculamos la estatura en centímetros
singer$estatura.m <- singer$height * 2.54
# calculamos el valor de f dentro de cada grupo (soprano, bajo, ...)
singer.ord <- arrange(group_by(singer, voice.part), estatura.m)
singer.cuant <- mutate(singer.ord,
n = n(),
valor.f = (1:n[1] - 0.5)/n[1]
)
ggplot(singer.cuant, aes(x = valor.f, y = estatura.m)) +
geom_point() +
facet_wrap(~voice.part, ncol = 2)
En este ejemplo notamos que las dispersiones son más o menos similares a lo largo de los grupos, aunque parece que Tenor 1 muestra una dispersión un poco mayor. Observamos también un efecto de redondeo en Soprano 1: la gráfica correspondiente tiene en el centro una sección plana, que es precedida de pendientes altas. Bajo 2 da alguna indicación de sesgo a la izquierda (aunque no muy fuerte), mientras que Tenor 2 tiene algo de sesgo a la derecha. También podemos ver que conforme baja la tesitura, las gráficas se desplazan hacia arriba (medianas más altas para tesituras más bajas). Finalmente, los datos que salen del patrón de cada grupo son claramente identificables, por ejemplo, en Tenor 2 y Alto 1 hay algunos cantantes muy altos en relación a su grupo.
Diagramas de caja y brazos
Los diagramas de caja y brazos son muy populares, e intentan mostrar gráficamente algo similar al resumen de cinco números de Tukey:
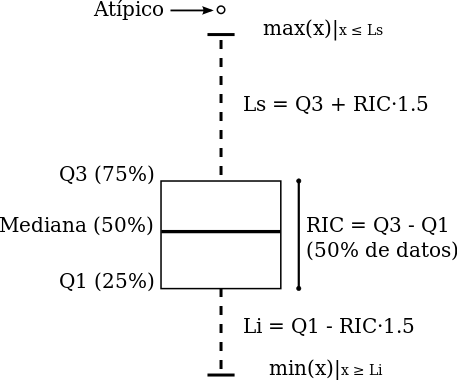
Imagen de Wikipedia.
Como vemos en la imagen superior el método muestra la mediana como una línea horizontal (medida de tendencia central), los bordes de la caja indican los cuartiles inferior y superior (o cuantiles 0.25 y 0.75). La distancia entre estos dos se conoce como rango intercuartílico o IQR por sus siglas en inglés, el IQR es una medida de dispersión. Alrededor del 50% de los datos están entre los cuartiles inferior y superior, es así que si el rango intercuartílico es chico los datos de enmedio están muy cercanos alrededor de la mediana, si el rango intercunatílico es grande los datos de enmedio están dispersos alrededor de la mediana. Adicionalmente, las distancias relativas de los cuartiles a la mediana nos dan información de la forma de la distribución, si una es mayor a la otra la distribucción está sesgada.Las líneas punteadas del diagrama superior indican los valores adyacentes, el valor adyacente superior se calcula de la siguiente forma: se toma el dato más grande que está a no más de \(1.5IQR\) del cuartil superior. Los valores adyacentes también nos dan un resumen de la forma y dispersión, pero lo hacen para los valores extremos, o colas de la distribución.
Finalmente, los datos mayores (o menores) a los valores adyacentes se grafican de manera individual como puntos. Si hay datos atípicos suelen aparecer como estos puntos graficados individualmente.
En el caso de los cantantes obtenemos la siguiente gráfica:
singer.medians <- mutate(group_by(singer, voice.part),
mediana = median(estatura.m))
ggplot(singer.medians, aes(x = voice.part, y = estatura.m)) +
geom_boxplot() +
geom_jitter(position = position_jitter(height = 0, width = 0.2),
color = "darkgray") +
geom_point(aes(y = mediana), colour = "red", size = 4) +
coord_flip()
- Recordemos los datos de ozono en Tlalpan e Iztapalapa:

a. Simétrica.
b. Tiene sesgo a la derecha.
c. Tiene sesgo a la izquierda.
¿Obtenemos la misma interpretación que para las gráficas de cuantiles? ¿En qué son mejores o peores?
Gráficas de cuantil-cuantil (Q-Q)
Una de las técnicas más poderosas para comparar visualmente la distribución de datos, es la gráfica de cuantil-cuantil. Aún cuando los histogramas, los diagramas de caja y brazos y la comparación entre gráficas de cuantiles son útiles, la gráfica de cuantil-cuantil es generalmente la mejor manera de hacer la tarea de comparación.
El método consiste en graficar cuantiles de un conjunto de datos contra los cuantiles correspondientes a otro conjunto de datos.
Grafica cuantil-cuantil. Si tenemos dos conjuntos de datos \[x_1,x_2...,x_n, y_1,y_2...,y_m\] ordenados de menor a mayor y procedemos como sigue:
Si \(m=n\) entonces \(x_i\) es el cuantil \((i-0.5)/n\) del primer conjunto y \(y_i\) es el cuantil \((i-0.5)/n\) del segundo conjunto. Graficamos entonces los pares \((x_i, y_i)\).
Si \(m<n\), entonces \(y_i\) es el cuantil \((i-0.5)/m\) del segundo conjunto, y necesitamos encontrar el cuantil \((i-0.5)/m\) del primer conjunto: par esto interpolamos. De esta manera, el número de puntos en la gráfica es \(m\) (en general, el mínimo de \(m\) y \(n\))
Ejemplos: Simulación
Los datos de los siguientes ejemplos son simulados. En todos los casos, los conjuntos de datos contienen 80 valores y en todas las gráficas, el mismo conjunto corresponde al eje horizontal.
En esta primer gráfica, las variables tienen distribuciones similares, pero una está desplazada con respecto a la otra: la diferencia más notable es que todos los cuantiles de una están desplazados en relación a la otra.
set.seed(100)
dat_1 <- qqplot(rnorm(80, mean=0, sd=1), rnorm(80, mean=2,sd=1), plot.it = FALSE)
ggplot(as.data.frame(dat_1), aes(x, y)) +
geom_point() +
xlim(c(-1,4)) +
ylim(c(-1,4)) +
geom_abline(intercept=0, slope = 1)Warning in loop_apply(n, do.ply): Removed 12 rows containing missing
values (geom_point).
- En la segunda gráfica, una distribución tiene más dispersión que la torra. ¿cuál?
- La correspondiente al eje horizontal.
- La correspondiente al eje vertical.

En la siguiente, una tiene sesgo con respecto a la otra. En relación a los datos simulados de una \(Normal(0,1)\) (eje horizontal), la cola izquierda de la variable en el eje vertical está más concentrada cerca de la mediana, mientras que la cola derecha está más lejana.
dat_1 <- qqplot(rnorm(80, mean=0, sd=1), rexp(80)-1, plot.it = FALSE)
ggplot(as.data.frame(dat_1), aes(x, y)) +
geom_point() +
xlim(c(-2,3)) +
ylim(c(-2,3)) +
geom_abline(intercept=0, slope = 1)Warning in loop_apply(n, do.ply): Removed 7 rows containing missing values
(geom_point).
La última gráfica no presenta ningún patrón tan claro como los anteriores. Aunque la gráfica sugiere algunas diferencias en las colas izquierdas, la variable en el eje vertical fue producida bajo la misma distribución que la del eje horizontal. En este caso, concluimos que la distribuciones son muy similares.
dat_1 <- qqplot(rnorm(80, mean=0, sd=1), rnorm(80, mean=0, sd=1),
plot.it = FALSE)
ggplot(as.data.frame(dat_1), aes(x, y)) +
geom_point() +
xlim(c(-2,3)) +
ylim(c(-2,3)) +
geom_abline(intercept=0, slope = 1)Warning in loop_apply(n, do.ply): Removed 3 rows containing missing values
(geom_point).