Sección 8 Propiedades teóricas de MLE
El método de máxima verosimiltud es uno de los métodos más utilizados en la inferencia estadística paramétrica. En esta sección estudiaremos las propiedades teóricas que cumplen los estimadores de máxima verosimilitud (\(\textsf{MLE}\)) y que han ayudado en su casi adopción universal.
Estas propiedades de los \(\textsf{MLE}\) son válidas siempre y cuando el modelo \(f(x; \theta)\) satisfaga ciertas condiciones de regularidad. En particular veremos las condiciones para que los estimadores de máxima verosimilitud sean: consistentes, asintóticamente normales, asintóticamente insesgados, asintóticamente eficientes, y equivariantes.
Los estimadores \(\textsf{MLE}\) en ocasiones son malinterpretados como una estimación puntual en la inferencia, y por ende, incapaces de cuantificar incertidumbre. A lo largo de estas notas hemos visto cómo extraer intervalos de confianza por medio de simulación y por lo tanto incorporar incertidumbre en la estimación. Sin embargo, hay otros maneras de reportar incertidumbre para \(\textsf{MLE}\). Y hablaremos de ello en esta sección.
A lo largo de esta sección asumiremos muestras de la forma \[\begin{align} X_1, \ldots, X_n \overset{\text{iid}}{\sim} f(x; \theta^*), \end{align}\] donde \(\theta^*\) es el valor verdadero —que suponemos desconocido pero fijo— del parámetro \(\theta \in \Theta\), y sea \(\hat \theta_n\) el estimador de máxima verosimilitud de \(\theta.\)
Ejemplo
Usaremos este ejemplo para ilustrar los diferentes puntos teóricos a lo largo de esta sección. Consideremos el caso de una muestra de variables binarias que registran el éxito o fracaso de un experimento. Es decir, \(X_1, \ldots, X_n \sim \textsf{Bernoulli}(p),\) donde el párametro desconocido es el procentaje de éxitos. Éste último denotado por \(p.\) Este ejemplo lo hemos estudiado en secciones pasadas, y sabemos que el \(\textsf{MLE}\) es \[\begin{align} \hat p_n = \frac{S_n}{n} = \bar X_n, \end{align}\] donde \(S_n= \sum_i X_i\) es el número total de éxitos en la muestra.
La figura siguiente ilustra el estimador \(\hat p_n\) como función del número de observaciones en nuestra muestra. Podemos apreciar cómo el promedio parece estabilizarse alrededor del verdadero valor de \(p^* = 0.25\) cuando tenemos una cantidad suficientemente grande de observaciones.
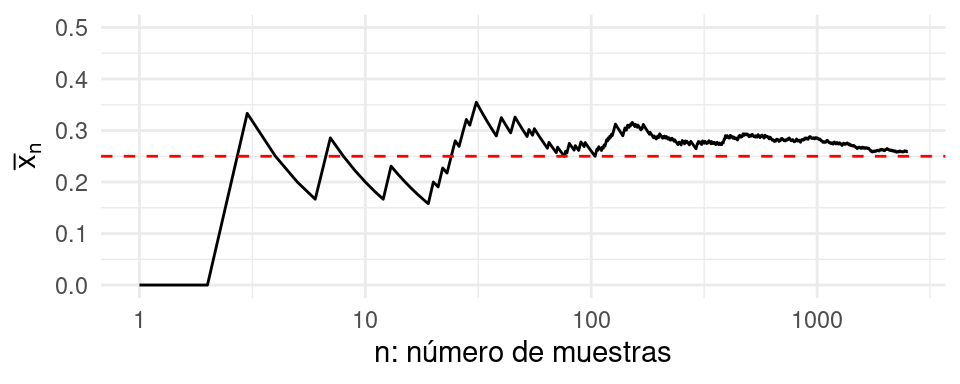
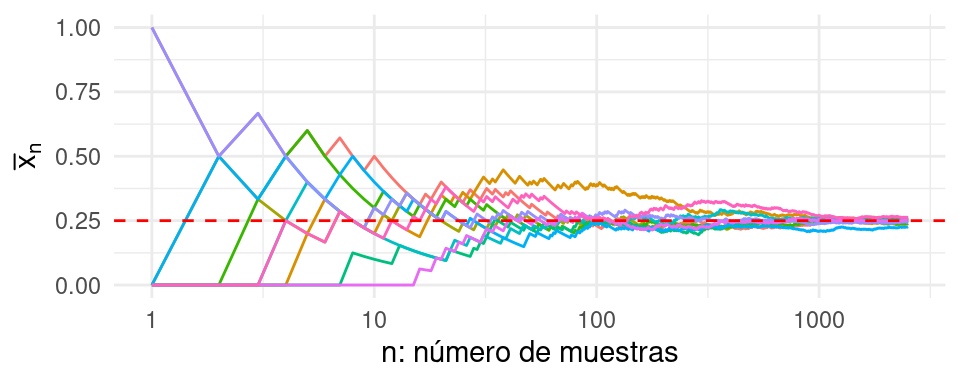
Como es de esperarse, diferentes muestras tendrán diferentes valores de \(n\) dónde las trayectorias parezca que se haya estabilizado (Ver figura siguiente). Sin embargo, se puede notar que este comportamiento parece estar controlado y son raras las trayectorias que se encuentran más lejos.
 Los conceptos siguientes nos permitirán cuantificar el porcentaje de
trayectorias que se mantienen cercanas a \(p^*,\) en el caso límite de un número
grande de observaciones, cuando trabajemos con estimadores de máxima
verosimilitud. Más aún, nos permitirán cracterizar la distribución para dicho
límite y aprenderemos de otras propiedades bajo este supuesto asintótico.
Los conceptos siguientes nos permitirán cuantificar el porcentaje de
trayectorias que se mantienen cercanas a \(p^*,\) en el caso límite de un número
grande de observaciones, cuando trabajemos con estimadores de máxima
verosimilitud. Más aún, nos permitirán cracterizar la distribución para dicho
límite y aprenderemos de otras propiedades bajo este supuesto asintótico.
Consistencia
Es prudente pensar que para un estimador, lo que nos interesa es que conforme más información tengamos, más cerca esté del valor desconocido. Esta propiedad la representamos por medio del concepto de consistencia. Para hablar de esta propiedad necesitamos definir un tipo de convergencia para una secuencia de variables aleatorias, convergencia en probabilidad.
\[\lim_{n \rightarrow \infty} \mathbb{P}(|X_n - X| > \epsilon) = 0.\]
Ahora, definimos un estimador consistente como:Definición. Un estimador \(\tilde \theta_n\) es consistente si converge en probabilidad a \(\theta^*.\) Donde \(\theta^*\) denota el verdadero valor del parámetro, que asumimos fijo.
Teorema. Sea \(X_n \sim f(X; \theta^*),\) una muestra iid, tal que \(f(X; \theta)\) cumple con ciertas condiciones de regularidad. Entonces, \(\hat \theta_n,\) el estimador de máxima verosimilitud, converge en probabilidad a \(\theta^*.\) Es decir, \(\hat \theta_n\) es consistente.
La demostración de este teorema la pueden encontrar en Wasserman (2013).
Ejemplo
El estimador \(\hat p_n\) es consistente. Esto quiere decir que el estimador se vuelve más preciso conforme obtengamos más información. En general esta es una propiedad que los estimadores deben satisfacer para ser útiles en la práctica. La figura siguiente muestra el estimador \(\hat p_n\) como función del número de observaciones utilizado. Distintas curvas corresponden a distintas realizaciones de muestras obtenidas del modelo (\(B = 500\)).
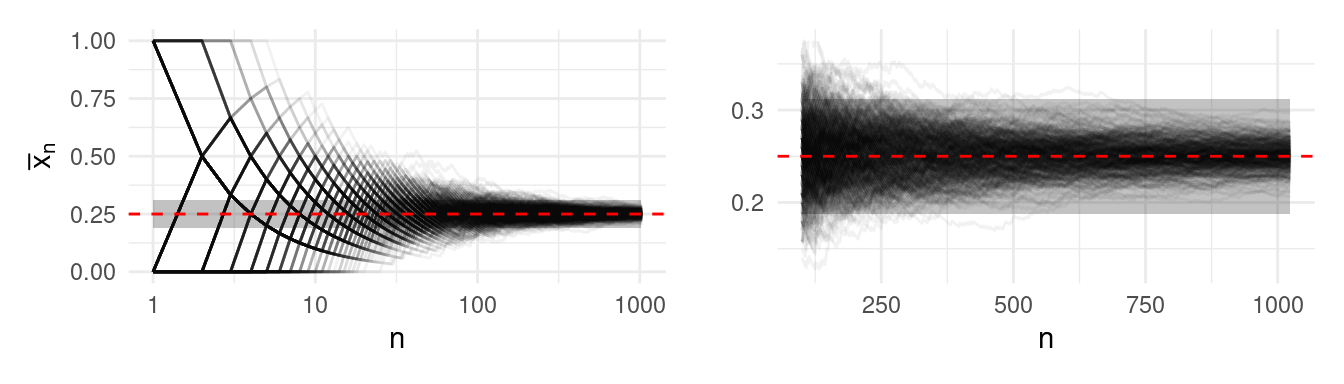
Nota que la banda definida por \(\epsilon\) se puede hacer tan pequeña como se requiera, lo único que sucederá es que necesitaremos un mayor número de observaciones para garantizar que las trayectorias de los estimadores \(\hat p_n\) se mantengan dentro de las bandas con alta probabilidad.
Equivarianza del \(\textsf{MLE}\)
Muchas veces nos interesa reparametrizar la función de verosimilitud con el motivo de simplificar el problema de optimización asociado, o simplemente por conveniencia interpretativa. Por ejemplo, si el parámetro de interés es tal que \(\theta \in [a, b],\) entonces encontrar el \(\textsf{MLE}\) se traduce en optimizar la log-verosimilitud en el espacio restringido al intervalo \([a,b].\) En este caso, los métodos tradicionales de búsqueda local por descenso en gradiente podrían tener problemas de estabilidad cuando la búsqueda se realice cerca de las cotas.
El concepto de equivarianza nos dice que si el cambio de coordenadas parametrales está definida, y si este cambio de variable se realiza por medio de una función bien comportada (derivable y cuya derivada no es cero), entonces la solución de encontrar el \(\textsf{MLE}\) en las coordenadas originales y transformar, es igual a realizar la inferencia en las coordenadas fáciles.
Teorema. Sea \(\tau = g(\theta)\) una función de \(\theta\) bien comportada. Entonces si \(\hat \theta_n\) es el \(\textsf{MLE}\) de \(\theta,\) entonces \(\hat \tau_n = g(\hat \theta_n)\) es el \(\textsf{MLE}\) de \(\tau.\)
Ejemplo
El concepto de equivarianza lo ilustraremos para nuestro ejemplo de esta sección. En particular la parametrización la realizamos por cuestiones de interpretación como un factor de riesgo.
Como hemos visto estimador \(\hat p_n\) es equivariante. Es importante mencionar que esta propiedad es general para cualquier tamaño de muestra. Es decir, no descansa en supuestos de muestras grandes. Supongamos que nos interesa estimar el momio de éxitos (bastante común en casas de apuestas). El momio está definido como \[ \theta = \frac{p}{1-p},\] y podemos rescribir la función de verosimilitud en términos de este parámetro. Sustituyendo \(p = \frac{\theta}{1+\theta}\) en \(\mathcal{L}_n(p)\) obtenemos \[\begin{align} \mathcal{L}_n(\theta) = \left( \frac{\theta}{1 + \theta} \right)^{S_n} \left(\frac{1}{1 + \theta} \right)^{n - S_n}, \end{align}\] cuya función encuentra su máximo en \[\begin{align} \hat \theta_n = \frac{\bar X_n}{ 1 - \bar X_n}. \end{align}\]
Comprueba que el estimador de arriba para \(\theta\) es el MLE.
Normalidad asintótica
Está propiedad nos permite caracterizar la distribución asintótica del MLE. Es decir, nos permite caracterizar la incertidumbre asociada una muestra suficientemente grande por medio de una distribución Gaussiana. Esto es, bajo ciertas condiciones de regularidad, \[\hat \theta_n \overset{.}{\sim} \mathsf{N}( \theta^*, \mathsf{ee}^2),\]
donde \(\mathsf{ee}\) denota el error estándar del \(\textsf{MLE},\) \(\mathsf{ee} = \mathsf{ee}(\hat \theta_n) = \sqrt{\mathbb{V}(\hat \theta_n)}\).
Esta distribución se puede caracterizar de manera aproximada por métodos analíticos. Para esto necesitamos las siguientes definiciones.
Definición. La función de score está definida como \[\begin{align} s(X; \theta) = \frac{\partial \log f(X; \theta)}{\partial \theta}. \end{align}\]
La información de Fisher está definida como \[\begin{align} I_n(\theta) &= \mathbb{V}\left( \sum_{i = 1}^ns(X_i; \theta) \right) \\ &= \sum_{i = 1}^n \mathbb{V} \left(s(X_i; \theta) \right) \end{align}\]
Estas cantidades nos permiten evaluar qué tan fácil será identificar el mejor modelo dentro de la familia parámetrica \(f(X; \theta)\). La función de score nos dice qué tanto cambia locamente la distribución cuando cambiamos el valor del parámetro. Calcular la varianza, nos habla de la dispersión de dicho cambio a lo largo del soporte de la variable aleatoria \(X.\) Si \(I_n(\theta)\) es grande entonces el cambio de la distribución es muy importante. Esto quiere decir que la distribución es muy diferente de las distribuciones cercanas que se generen al evaluar en \(\theta\)s diferentes. Por lo tanto, si \(I_n(\theta)\) es grande, la distribución será fácil de identificar cuando hagamos observaciones.
La información de Fisher también nos permite caracterizar de forma analítica la varianza asíntotica del \(\textsf{MLE}\) pues la aproximación \(\mathsf{ee}^2 \approx \frac{1}{I_n(\theta^*)}\) es válida.
El siguiente resultado utiliza la propiedad de la función de score: \(\mathbb{E}[s(X; \theta)] = 0,\) que implica que \(\mathbb{V} \left(s(X_i; \theta) \right) = \mathbb{E}[s^2(X; \theta)],\) y permite a su vez un cómputo más sencillo de la información de Fisher.
Teorema. El cálculo de la información de Fisher para una muestra de tamaño \(n\) se puede calcular de manera simplificada como \(I_n(\theta) = n \, I(\theta).\) Por otro lado, tenemos la siguiente igualdad \[ I(\theta) = - \mathbb{E}\left( \frac{\partial^2 \log f(X; \theta)}{\partial \theta^2} \right).\]
Con estas herramientas podemos formular el teorema siguiente.
Teorema. Bajo ciertas condiciones de regularidad se satisface que \(\mathsf{ee} \approx \sqrt{1/I_n(\theta^*)}\) y \[ \hat \theta_n \overset{d}{\rightarrow} \mathsf{N}( \theta^*, \mathsf{ee}^2).\]
El resultado anterior es teóricamente interesante y nos asegura un comportamiento controlado conforme tengamos más observaciones disponibles. Sin embargo, no es práctico pues no conocemos \(\theta^*\) en la práctica y por consiguiente no conoceríamos la varianza. Sin embargo, también podemos aplicar el principio de plug-in y caracterizar la varianza de la distribución asintótica por medio de \[\hat{\mathsf{ee}} = \sqrt{1/I_n(\hat \theta_n)}.\]
Esto último nos permite constuir intervalos de confianza, por ejemplo al 95%, a través de \[ \hat \theta_n \pm 2 \, \hat{\mathsf{ee}}.\] Asimismo, el teorema de Normalidad asintótica nos permite establecer que el \(\textsf{MLE}\) es asíntoticamente insesgado. Es decir, \[\lim_{n \rightarrow \infty}\mathbb{E}[\hat \theta_n] = \theta^*.\]
Definición. Sea una muestra \(X_1, \ldots, X_n \overset{iid}{\sim} f(X; \theta^*)\). Un estimador \(\tilde \theta_n\) es insesgado si satisface que \[\mathbb{E}[\tilde \theta_n] =\theta^*.\]
El sesgo del estimador es precisamente la diferencia: \(\textsf{Sesgo} = \mathbb{E}[\tilde \theta_n] - \theta^*.\)
Ejemplo: Información de Fisher
En el caso Bernoulli obtenemos \(I_n(\theta) = \frac{n}{\theta(1-\theta)}\), si \(n = 20\) podemos comparar con \(\theta=0.5, 0.7, 0.8\),
library(patchwork)
# Verosimilitud X_1,...,X_n ~ Bernoulli(theta)
L_bernoulli <- function(n, S){
function(theta){
theta ^ S * (1 - theta) ^ (n - S)
}
}
xy <- data.frame(x = 0:1)
l_b1 <- ggplot(xy, aes(x = x)) +
stat_function(fun = L_bernoulli(n = 20, S = 10)) +
xlab(expression(theta)) +
ylab(expression(L(theta))) +
labs(title = "Verosimilitud", subtitle = "n=20, S = 10") +
ylim(0, 5e-05)
l_b2 <- ggplot(xy, aes(x = x)) +
stat_function(fun = L_bernoulli(n = 20, S = 14)) +
xlab(expression(theta)) +
ylab(expression(L(theta))) +
labs(title = "Verosimilitud", subtitle = "n=20, S = 14") +
ylim(0, 5e-05)
l_b3 <- ggplot(xy, aes(x = x)) +
stat_function(fun = L_bernoulli(n = 20, S = 16)) +
xlab(expression(theta)) +
ylab(expression(L(theta))) +
labs(title = "Verosimilitud", subtitle = "n=20, S = 19") +
ylim(0, 5e-05)
l_b1 + l_b2 + l_b3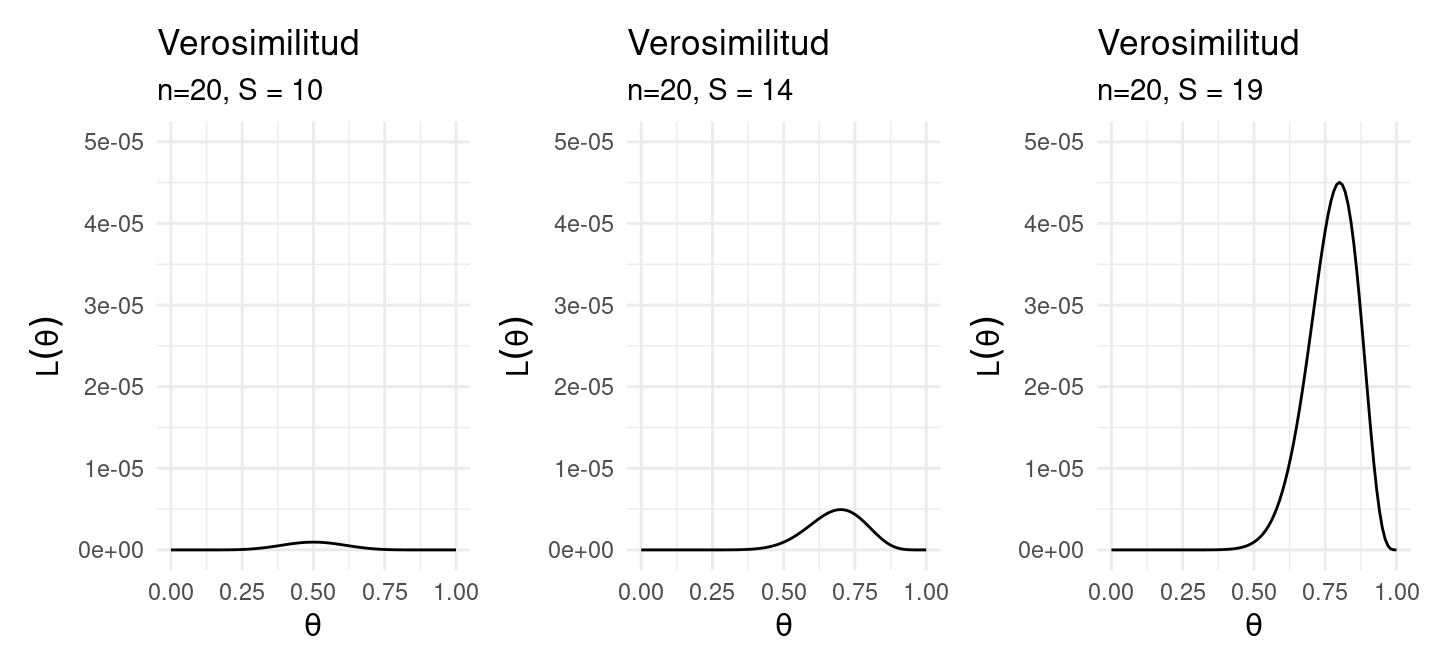
Ejemplo: Normalidad
Regresando a nuestro ejemplo. Veremos empiricamente que el estimador \(\hat \theta_n\) es asintóticamente normal. Esta propiedad la hemos visto anteriormente para un caso muy particular. Lo vimos en el TLC para el caso de promedios, \(\bar X_n,\) que en nuestro ejemplo corresponde a \(\hat p_n\). Como hemos visto, esta propiedad la satisface cualquier otro estimador que sea máximo verosímil. Por ejemplo, podemos utilizar el \(\mathsf{MLE}\) de los momios. La figura que sigue muestra la distribución de \(\hat \theta_n\) para distintas remuestras \((B = 500)\) con distintos valores de \(n.\)
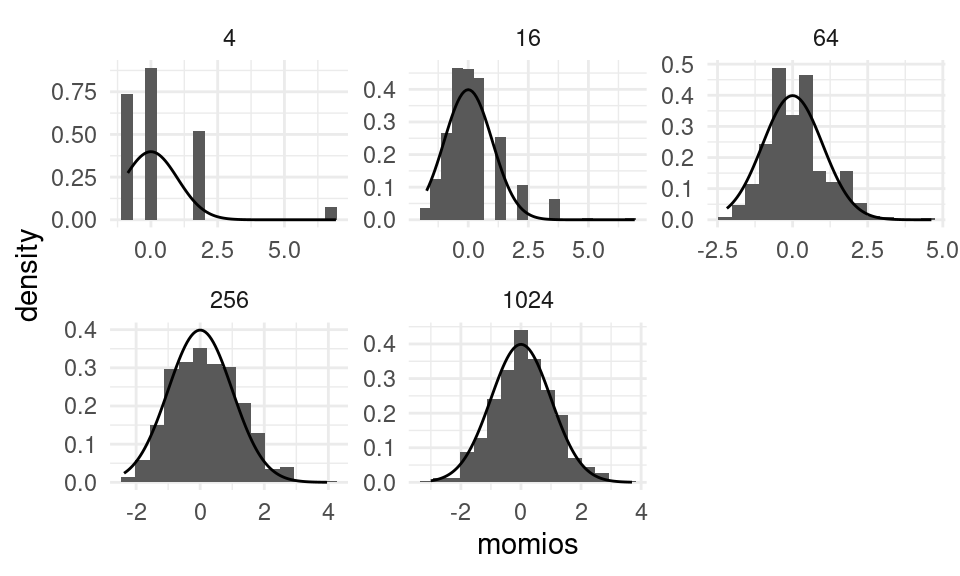
El gráfico anterior valida empíricamente la distribución asintótica para casos de muchas observaciones. A continuación ilustraremos cómo explotar este resultado para obtener intervalos de confianza.
Para el caso de \(\hat p_n\) hemos visto que el error estándar se calcula analíticamente como \[\textsf{ee}_p^2 = \mathbb{V}(\hat p_n) = \mathbb{V}\left(\frac1n \sum_{i = 1}^n x_i\right) = \frac{p^* (1 - p^*)}{n}.\]
Éste empata con el valor del error estándar asintótico \[\textsf{ee}_p^2 \approx \sqrt{\frac{1}{I_n(p^*)}},\] pues la información de Fisher es igual a \[I_n(p) = n \, I(p) = \frac{n}{p ( 1- p)}.\] En este caso podemos utilizar el estimador plug-in, \(\hat{\textsf{ee}}_p = \textsf{ee}_p(\hat p_n).\) Para estimar el momio, \(\theta,\) el cálculo no es tan fácil pues tendríamos que calcular de manera analítica la varianza de un cociente \[\textsf{ee}_\theta^2 = \mathbb{V}\left( \frac{\hat p_n}{1-\hat p_n}\right).\] Utilizando la distirbución asintótica, el error estándar se puede calcular mediante \[\textsf{ee}_\theta \approx \sqrt{\frac{1}{I_n(\theta^*)}} = \sqrt{\frac{\theta (1 + \theta)^2 }{n}}.\] A continuación mostramos los errores estándar para nuestro ejemplo utilizando la distribución asintótica y por medio de la distribución de bootstrap. Como es de esperarse, ambos coinciden para muestras relativamente grandes.
# Genero muestra
muestras <- tibble(tamanos = 2**seq(4,7)) %>%
mutate(obs = map(tamanos, ~rbernoulli(., p = p_true)))
calcula_momio <- function(x){
x / (1 - x)
}
calcula_ee_momio <- function(x){
sqrt(((1+x)**2) * x)
}
# Calculo MLE
muestras_est <- muestras %>%
group_by(tamanos) %>%
mutate(media_hat = map_dbl(obs, mean),
media_ee = sqrt(media_hat * (1 - media_hat)/tamanos),
momio_hat = calcula_momio(media_hat),
momio_ee = calcula_ee_momio(momio_hat)/sqrt(tamanos))
# Calculo por bootstrap
muestras_boot <- muestras_est %>%
group_by(tamanos) %>%
mutate(sims_muestras = map(tamanos, ~rerun(1000, sample(muestras %>% filter(tamanos == ..1) %>% unnest(obs) %>% pull(obs),
size = ., replace = TRUE))),
sims_medias = map(sims_muestras, ~map_dbl(., mean)),
sims_momios = map(sims_medias, ~map_dbl(., calcula_momio)),
media_boot = map_dbl(sims_medias, mean),
momio_boot = map_dbl(sims_momios, mean),
media_ee_boot = map_dbl(sims_medias, sd),
momio_ee_boot = map_dbl(sims_momios, sd)
)## # A tibble: 4 × 5
## # Groups: tamanos [4]
## tamanos momio_hat momio_boot momio_ee momio_ee_boot
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 16 0.333 0.367 0.192 0.236
## 2 32 0.333 0.342 0.136 0.140
## 3 64 0.123 0.123 0.0492 0.0498
## 4 128 0.407 0.417 0.0793 0.0800Comprueba las fórmulas para los errores estándar tanto para la probabilidad de éxito como para los momios.
El método delta
El ejercicio anterior nos sugiere una pregunta natural: Cómo establecer la distribución asintótica de un estimador cuando ya se conoce la de una pre-imagen de él? Es decir, si ya conocemos la distribución de \(\theta,\) podemos establecer la distribución de \(\tau = g(\theta)?\)
La respuesta es afirmativa y la enunciamos por medio de un teorema. El resultado se conoce como el método delta.
Teorema. Si \(\tau = g(\theta)\) es una función diferenciable y \(g'(\theta) \neq 0\), entonces
\[\hat \tau_n \overset{d}{\rightarrow} \mathsf{N}( \tau^*, \hat{\mathsf{ee}}^2_\tau),\]donde \(\hat \tau_n = g(\hat \theta_n)\) y
\[\hat{\mathsf{ee}}_\tau = \bigg| g'(\hat \theta_n) \bigg| \times \hat{\mathsf{ee}}_\theta(\hat \theta_n).\]
Por ejemplo, este resultado lo podemos utilizar para nuestro experimento de Bernoullis. Pues \(g(p) = \frac{p}{1-p}\) es una función diferenciable y por lo tanto \[\hat{\mathsf{ee}}_\theta = \sqrt{\frac1n} \times \left[ \hat p_n^{1/2} (1-\hat p_n)^{-3/2}\right].\]
Comprueba la fórmula del método delta para el momio en función de la fracción de éxitos, y también comprueba que de el mismo resultado analítico que habías calculado en el ejercicio anterior.
Optimalidad del \(\textsf{MLE}\)
Consideremos el caso de una muestra iid \(X_1, \ldots, X_n \sim \mathsf{N}(\theta, \sigma^2).\) Y consideremos dos estimadores para \(\theta.\) El primero será la media muestral \(\bar X_n\) y el segundo la mediana muestral, la cual denotaremos por \(\tilde \theta_n.\) Sabemos que ambos son insesgados. Por lo tanto, en promedio emiten estimaciones correctas. Pero ¿cómo escogemos cual utilizar?
Un criterio para comparar estimadores es el error cuadrático medio (\(\textsf{ECM}\), por sus siglas en inglés).
Definición. El error cuadrático medio de un estimador \(\tilde \theta_n\) se calcula como \[\textsf{ECM}[\tilde \theta_n] = \mathbb{E}[(\tilde \theta_n - \theta^*)^2].\]
Por lo tanto, el \(\textsf{ECM}\) mide la distancia promedio entre el estimador y el valor verdadero valor del parámetro. La siguiente igualdad es bastante útil para comparar dos estimadores.
\[\textsf{ECM}[\tilde \theta_n] = \mathbb{V}\left(\tilde \theta_n\right) + \textsf{Sesgo}\left[\tilde \theta_n\right]^2.\]
Por lo tanto si dos estimadores son insesgados, uno es más eficiente que el otro si su varianza es menor.
La media sabemos que es el \(\textsf{MLE}\) y por el TCL tenemos que \[\sqrt{n} \left( \bar X_n - \theta \right) \overset{d}{\rightarrow} \mathsf{N}( 0, \sigma^2).\]
La mediana, en contraste, tiene una distribución asintótica \[\sqrt{n} \left( \tilde X_n - \theta \right) \overset{d}{\rightarrow} \mathsf{N}\left( 0, \sigma^2 \frac{\pi}{2}\right),\]
es decir tiene una varianza ligeramente mayor. Por lo tanto, decimos que la mediana tiene una eficiencia relativa con respecto a la media del \(.63 \% (\approx 2/\pi)\). Es decir, la mediana sólo utliza una fracción de los datos comparado con la media.
El siguiente teorema, la desigualdad de Cramer-Rao, nos permite establecer esta resultado de manera mas general para cualquier estimador insesgado.
Teorema. Sea \(\tilde \theta_n\) cualquier estimador insesgado de \(\theta\) cuyo valor verdadero es \(\theta^*,\) entonces \[\begin{align} \mathbb{V}(\tilde \theta_n) \geq \frac{1}{n I(\theta^*)}. \end{align}\]
Un estimador insesgado que satisfaga esta desigualdad se dice que es eficiente. Nota que el lado derecho de la desigualdad es precisamente la varianza asintótica del \(\textsf{MLE}.\) Por lo tanto, éste es asintóticamente eficiente.
Es importante hacer enfásis en que la optimalidad del \(\textsf{MLE}\) es un resultado asintótico. Es decir, sólo se satisface cuando tenemos un número suficiente de observaciones. Qué tan grande debe ser el tamaño de muestra varia de problema a problema. Es por esto que para muestras de tamaño finito se prefieren estimadores que minimicen el \(\textsf{ECM},\) como cuando hacemos regresión ridge o utilizamos el estimador James–Stein para un vector de medias.