1.1 Introducción
La visualización de datos no trata de hacer gráficas “bonitas” o “divertidas”, ni de simplificar lo complejo o ayudar a una persona “que no entiende mucho” a entender ideas complejas. Más bien, trata de aprovechar nuestra gran capacidad de procesamiento visual para exhibir de manera clara aspectos importantes de los datos.
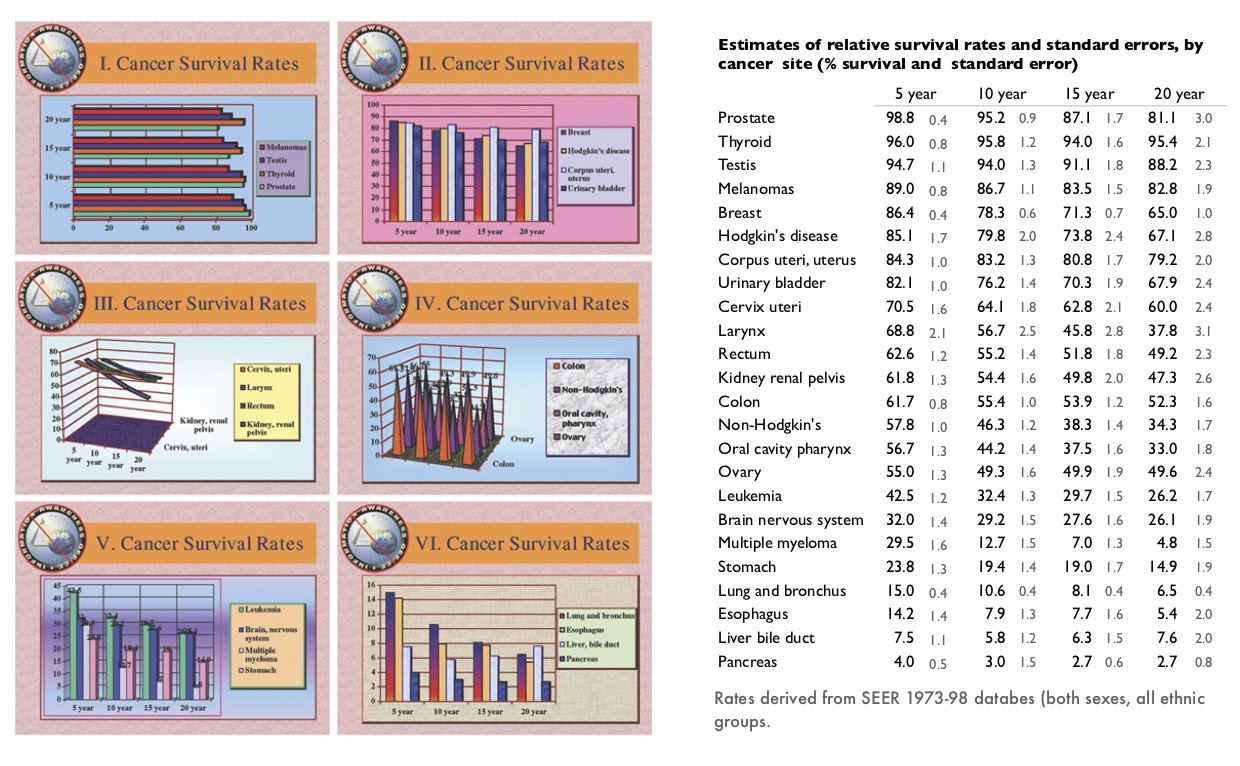
El siguiente ejemplo de (Tufte 2006), ilustra claramente la diferencia entre estos dos enfoques. A la izquierda están gráficas (más o menos típicas de Powerpoint) basadas en la filosofía de simplificar, de intentar no “ahogar” al lector con datos. El resultado es una colección incoherente, de bajo contenido, que no tiene mucho qué decir y que es, “indeferente al contenido y la evidencia”. A la derecha está una variación del rediseño de Tufte en forma de tabla, que en este caso particular es una manera eficiente de mostrar claramente los patrones que hay en este conjunto simple de datos.
¿Qué principios son los que soportan la efectividad de esta tabla sobre la gráfica de la derecha? Veremos que hay dos conjuntos de principios importantes: unos relacionados con el diseño y otros con la naturaleza del análisis de datos, independientemente del método de visualización.
Visualización de datos en la estadística
El estándar científico para contestar preguntas o tomar decisiones es uno que se basa en el análisis de datos: para contestar preguntas o tomar decisiones es necesario, en primer lugar, reunir todos los datos disponibles que puedan contener o sugerir alguna guía para entender mejor la pregunta o la decisión a la que nos enfrentamos. Esta recopilación de datos -que pueden ser cualitativos, cuantitativos, o una mezcla de los dos, debe entonces ser analizada para extraer información relevante para nuestro problema.
Tradicionalmente el análisis de datos se divide en dos distintos tipos de trabajo:
El trabajo exploratorio o de detective: ¿cuáles son los aspectos importantes de estos datos? ¿qué indicaciones generales muestran los datos? ¿qué tareas de análisis debemos empezar haciendo? ¿cuáles son los caminos generales para formular con precisión y contestar algunas preguntas que nos interesen?
- El trabajo inferencial, confirmatorio, o de juez: ¿cómo evaluar el peso de la evidencia de los descubrimientos del paso anterior? ¿qué tan bien soportadas están las respuestas y conclusiones por nuestro conjunto de datos?
Aunque en el proceso de inferencia las gráficas cada vez son más importantes, la visualización entra más claramente dentro del análisis exploratorio de datos. Y como en un principio no es claro como la visualización aporta al proceso de la inferencia, se le consideró por mucho tiempo como un área de poca importancia para la estadística: una herramienta que en todo caso sirve para comunicar ideas simples, de manera deficiente, y a personas poco sofisticadas.
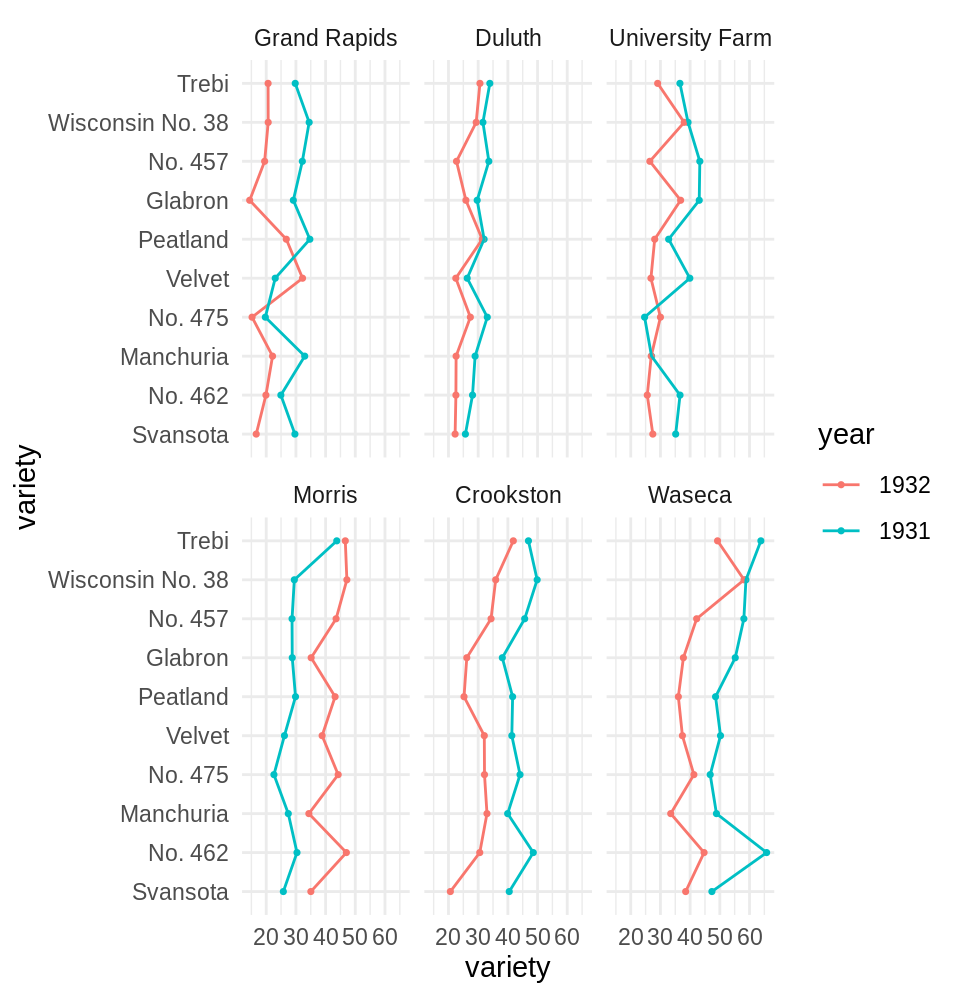
El peor lado de este punto de vista consiste en restringirse a el análisis estadístico rutinario Cleveland (1993): aplicar las recetas y negarse a ver los datos de distinta manera (¡incluso pensar que esto puede sesgar los resultados, o que nos podría engañar!). El siguiente ejemplo muestra un caso grave y real (no simulado) de este análisis estadístico rutinario (tomado de Cleveland (1994)).
A la derecha mostramos los resultados de un experimento de agricultura. Se cultivaron diez variedades de cebada en seis sitios de Minnesota, en \(1921\) y \(1932\). Este es uno de los primeros ejemplos en el que se aplicaron las ideas de Fisher en cuanto a diseño de experimentos.
En primer lugar, observamos:
- Los niveles generales de rendimiento varían mucho dependiendo del sitio: hay
mejores y peores sitios.
- Los rendimientos son típicamente más altos en 1931 que en 1932. Sin embargo, Morris es anómalo en cuanto a que el patrón no es consistente con el resto de los sitios.
- Hay variación considerable de las variedades dentro de cada sitio. ¿Existe alguna variedad que sea mejor que otras?
- Notamos claramente la anomalía en las diferencias: en el sitio Morris, el año 1932 fue mejor que el de 1931.
Estos datos fueron reanalizados desde la época en la que se recolectaron por muchos agrónomos. Hasta muy recientemente se detectó la anomalía en el comportamiento de los años en el sitio Morris, el cual es evidente en la gráfica. Investigación posterior ha mostrado que es muy plausible que en algún momento alguien volteó las etiquetas de los años en este sitio.
Este ejemplo muestra, en primer lugar, que la visualización es crucial en el proceso de análisis de datos: sin ella estamos expuestos a no encontrar aspectos importantes de los datos (errores) que deben ser discutidos - aún cuando nuestra receta de análisis no considere estos aspectos. Ninguna receta puede aproximarse a describir todas las complejidades y detalles en un conjunto de datos de tamaño razonable (este ejemplo, en realidad, es chico). Sin embargo, la visualización de datos, por su enfoque menos estructurado, y el hecho de que se apoya en un medio con un “ancho de banda” mayor al que puede producir un cierto número de cantidades resumen, es ideal para investigar estos aspectos y detalles.
Visualización popular de datos
Publicaciones populares (periódicos, revistas, sitios internet) muchas veces incluyen visualización de datos como parte de sus artículos o reportajes. En general siguen el mismo patrón que en la visión tradicionalista de la estadística: sirven más para divertir que para explicar, tienden a explicar ideas simples y conjuntos chicos de datos, y se consideran como una “ayuda” para los “lectores menos sofisticados”. Casi siempre se trata de gráficas triviales (muchas veces con errores graves) que no aportan mucho a artículos que tienen un nivel de complejidad mucho mayor (es la filosofía: lo escrito para el adulto, lo graficado para el niño).
Referencias
Cleveland, W.S. 1993. Visualizing Data. At&T Bell Laboratories. https://books.google.com.mx/books?id=V-dQAAAAMAAJ.
Cleveland, W.S. 1993. Visualizing Data. At&T Bell Laboratories. https://books.google.com.mx/books?id=V-dQAAAAMAAJ.
1994. The Elements of Graphing Data. AT&T Bell Laboratories. https://books.google.com.mx/books?id=KMsZAQAAIAAJ.Tufte, Edward R. 2006. Beautiful Evidence. Cheshire, CT: Graphics Press.