5.2 Interpretación frecuentista de probabilidad
Ya tenemos una interpretación intuitiva de probabilidad pero nos deja abierta la pregunta de como interpretar probabilidades en aplicaciones. Abordamos ahora la interpretación frecuentista de la probabilidad en la cuál las probabilidades se entienden como una aproximación matemática de frecuencias relativas cuando la frecuencia total tiende a infinito.
Una frecuencia relativa es una proporción que mide que tan seguido, o frecuente, ocurre una u otra cosa en una sucesión de observaciones. Pensemos en un experimento que se pueda repetir, por ejemplo, lanzar una moneda, lanzar un dado, el nacimiento de un bebé. Llamaremos ensayo a una repetición del experimento. Ahora, sea A un posible resultado del evento (obtener sol, obtener un 6, el bebé es niña), si A ocurre \(m\) veces en \(n\) ensayos, entonces la frecuencia relativa de A en \(n\) ensayos es \(m/n\).
Supongamos que lanzamos una moneda 10 veces y obtenemos los siguientes resultados:
lanzamientos_10 <- sample(c("A", "S"), 10, replace = TRUE)
lanzamientos_10
#> [1] "A" "S" "A" "A" "S" "S" "A" "S" "S" "S"Podemos calcular las secuencia de frecuencias relativas de águila:
cumsum(lanzamientos_10 == "A") # suma acumulada de águilas
#> [1] 1 1 2 3 3 3 4 4 4 4
cumsum(lanzamientos_10 == "A") / 1:10
#> [1] 1.000 0.500 0.667 0.750 0.600 0.500 0.571 0.500 0.444 0.400Una regla general, es que las frecuencias relativas basadas en un número mayor de observaciones son menos fluctuantes comparado con las frecuencias relativas basadas en pocas observaciones. Este fenómeno se conoce como la ley empírica de los promedios (y se formalizó después en las leyes de los grandes números):
n <- 1000
data_frame(num_lanzamiento = 1:n, lanzamiento = sample(c("A", "S"), n, replace = TRUE)) %>%
mutate(frec_rel = cummean(lanzamiento == "A")) %>%
ggplot(aes(x = num_lanzamiento, y = frec_rel)) +
geom_hline(yintercept = 0.5, color = "red", alpha = 0.5) +
geom_line(color = "darkgray") +
geom_point(size = 1.0) +
labs(y = "frecuencia relativa", title = "1000 volados", x = "lanzamiento")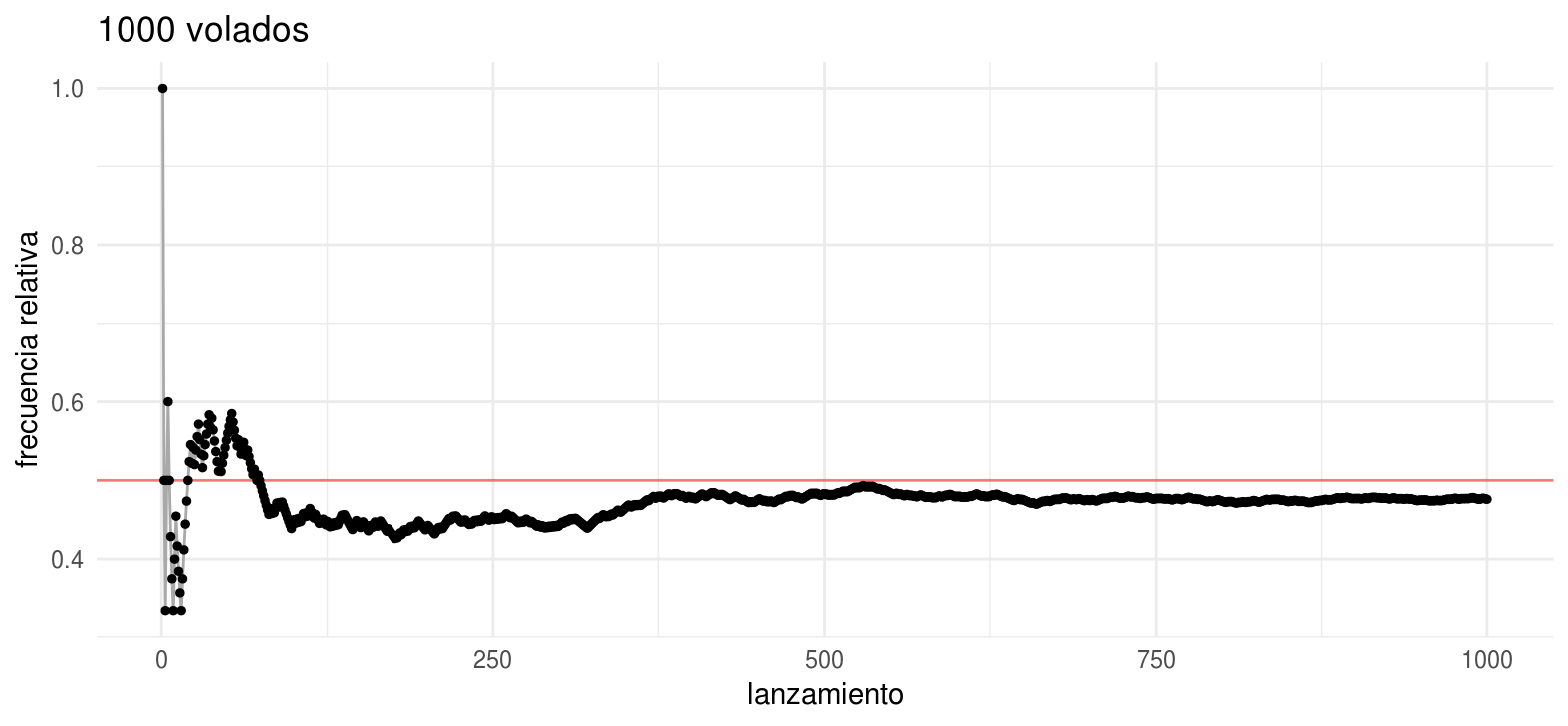
Veamos las frecuencias relativas para 3 series de 1000 lanzamientos.
lanzar <- function(n = 1000){
data_frame(num_lanzamiento = 1:n, lanzamiento = sample(c("A", "S"), n, replace = TRUE)) %>%
mutate(frec_rel = cummean(lanzamiento == "A"))
}
head(lanzar())
#> # A tibble: 6 x 3
#> num_lanzamiento lanzamiento frec_rel
#> <int> <chr> <dbl>
#> 1 1 S 0
#> 2 2 A 0.5
#> 3 3 S 0.333
#> 4 4 S 0.25
#> 5 5 S 0.2
#> 6 6 S 0.167
set.seed(31287931)
# usamos la función map_df del paquete purrr
map_df(1:3, ~lanzar(), .id = "serie") %>%
ggplot(aes(x = log(num_lanzamiento), y = frec_rel, color = as.character(serie))) +
geom_hline(yintercept = 0.5, color = "darkgray") +
geom_line() +
scale_x_continuous("lanzamiento", labels = exp,
breaks = log(sapply(0:10, function(i) 2 ^ i))) +
labs(color = "serie", y = "frecuencia relativa", title = "1000 volados")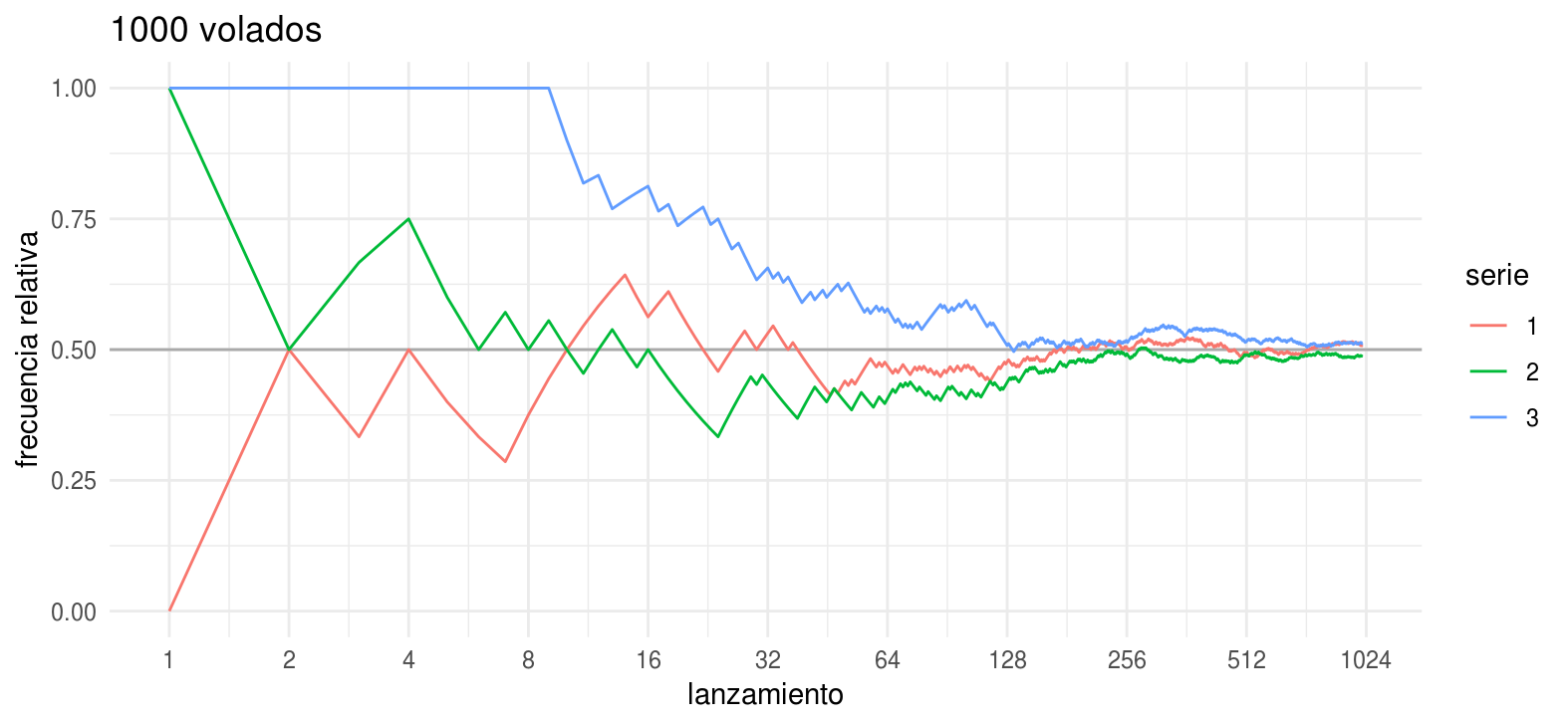
En la interpretación frecuentista, la probabilidad de un evento \(A\) es la estimación de la frecuencia relativa de \(A\) cuando el número de ensayos tiende a infinito. Si denotemos la proporción de veces que ocurre \(A\) en \(n\) ensayos por \(P_n(A)\), se espera que \(P_n(A)\) sea cercana a la probabilidad \(P(A)\) si \(n\) es grande: \[P_n(A) \approx P(A)\]
Veamos un ejemplo de calculo de una probabilidad como frecuencia relativa; el objetivo es entender cómo la interpretación frecuentista nos da el nivel de detalle correcto cuando suponemos resultados equiprobables.
Ejemplo: Lanzamiento de dos monedas
Supongamos que lanzamos dos monedas de manera simultánea. ¿Cuál es la probabilidad de que las dos monedas sean águila?
Las dos son águila o no, así que la posibilidad es 1/2.
Si definimos el resultado como el número de caras que se leen en las monedas, puede haber 0, 1 o 2. Si suponemos que estos tres resultados son igualmente probables, entonces la posibilidad es 1/3.
A pesar de que las monedas son similares supongamos que se pueden distinguir, llamémoslas moneda 1 y moneda 2. Ahora tenemos cuatro posibles resultados: AA, AS, SA, SS, (la primer letra corresponde a la cara observada en la moneda 1 y la segunda en la moneda 2). Si estos 4 resultados son igualmente probables entonces el evento AA tiene posibilidad de 1/4.
¿Cuál es la respuesta correcta?
En cuanto a teoría formal todas son correctas, cada escenario tiene supuestos de resultados equiprobables claramente enunciados y en base a éstos determina una probabilidad de manera correcta; sin embargo, los supuestos son diferentes y por tanto también las conclusiones. Únicamente una de las soluciones puede ser consistente con la interpretación frecuentista, ¿cuál es?
La primer respuesta es incorrecta pues supone probabilidad cero para el evento águila y sol. La solución dos, por otra parte, no es fácil de desacreditar, así que realicemos el experimento para encontrar la respuesta:
n <- 10000
moneda_1 <- sample(c("A", "S"), n, replace = TRUE)
moneda_2 <- sample(c("A", "S"), n, replace = TRUE)
sum(moneda_1 == moneda_2 & moneda_1 =="A") / n
#> [1] 0.257La respuesta 3 es la correcta, y lo que vemos es que incluso cuando el supuesto de igualmente probables es apropiado a un cierto nivel de descripción determinado, este nivel no es algo que se pueda juzgar usando únicamente matemáticas, sino que se debe juzgar usando una interpretación de la probabilidad, como frecuencias relativas en ensayos. Más aún, hay ejemplos donde las monedas no son justas, o el sexo de un bebé recién nacido, donde el supuesto de equiprobabilidad no es adecuado.