10.11 Modelos jerárquicos
Los modelos jerárquicos involucran varios parámetros de tal manera que las creencias de unos de los parámetros dependen de manera significativa de los valores de otros parámetros. Por ejemplo, consideremos el caso en el que tenemos varias monedas acuñadas en la misma casa de monedas, es razonable pensar que una fábrica sesgada a águilas tenderá a producir monedas con sesgo hacia águilas. La estimación del sesgo de una moneda depende de la estimación del sesgo de la fábrica que a su vez está influido por los datos de todas las monedas. Veremos que la estructura de dependenica a lo largo de los parámetros generan estimaciones mejor informadas para todos los parámetros.
Si pensamos únicamente en dos monedas que provienen de la misma casa de moneda tenemos:
Conocimientos iniciales de los posibles valores de los parámetros (sesgos de las monedas).
Tenemos conocimiento inicial de la dependencia de los parámetros por provenir de la misma fábrica.
Cuando observamos lanzamientos de las monedas actualizamos nuestras creencias relativas a los sesgos de las monedas y también actualizamos nuestras creencias acerca de la dependencia de los sesgos.
Recordemos el caso de lanzamientos de una moneda, le asignamos una inicial beta, recordemos que la distribución beta tienen dos parámetors \(a\) y \(b\):
\[p(\theta)=\frac{1}{B(a,b)}\theta^{a-1}(1-\theta)^{b-1}\]
Con el fin de hacer los parámetros más intuitivos los podemos expresar en términos de la media \(\mu\) y el tamaño de muestra \(K\), donde \(\mu\) es la media de nuestro conocimiento inicial y la confianza está reflejada en el tamaño de muestra \(K\). Entonces los parámetros correspondientes en la distribución beta son:
\[a=\mu K, b = (1-\mu)K\]
Ahora introducimos el modelo jerárquico. En lugar de especificar un valor particular para \(\mu\), consideramos que \(\mu\) puede tomar distintos valores (entre \(0\) y \(1\)), y definimos una distribución de probabilidad sobre esos valores. Podemos pensar que esta distribución describe nuestra incertidumbre acerca de la construcción de la máquina que manufactura las monedas.
Veamos que en el caso de más de una moneda el modelo permite que cada moneda tenga un sesgo distinto pero ambas tenderán a tener un sesgo cercano a \(\mu\), algunas aleatoriamente tendrán un valor de \(\theta\) mayor a \(\mu\) y otras menor. Entre más grande \(K\) mayor será la consistencia de la acuñadora y los valores \(\theta\) serán más cercanos a \(\mu\). Si observamos varios lanzamientos de una moneda tendremos información tanto de \(\theta\) como de \(\mu\).
Para hacer un análisis bayesiano aún nos hace falta definir la distribución inicial sobre los parámetros \(\mu\), usemos una distribución Beta:
\[p(\mu)=beta(\mu|A_{\mu}, B_{\mu})\]
donde \(A_{\mu}\) y \(B_{\mu}\) se conocen como hiperparámetros y son constantes. En este caso, consideramos que \(\mu\) se ubica típicamente cerca de \(A_{\mu}/(A_{\mu} + B_{\mu})\) y \(K\) se considera constante.
Modelo jerárquico una moneda
Recordemos que en el ejemplo de una moneda teníamos que la verosimilitud era Bernoulli:
\[p(x|theta) = \theta^x(1-\theta)^{1-x}\]
Y si utilizamos las iniciales Beta para \(\mu\) y \(\theta\) como discutimos arriba, solo nos resta aplicar la regla de Bayes con nuestros dos parámetros desconocidos \(\mu\) y \(\theta\):
\[p(\theta, \mu|x)=\frac{p(x|\theta,\mu)p(\theta,\mu)}{p(x)}\]
Hay dos aspectos a considerar en el problema:
La verosimilitud no depende de \(\mu\) por lo que \[p(x|\theta, \mu)=p(x|\theta)\]
La distribución inicial en el espacio de parámetros bivariado se puede factorizar:
\[p(\theta,\mu)=p(\theta|\mu)p(\mu)\]
Por lo tanto \[p(\theta,\mu|x)=\frac{p(x|\theta,\mu)p(\theta,\mu)}{p(x)}\] \[=\frac{p(x|\theta)p(\theta|\mu)p(\mu)}{p(x)}\] El siguiente modelo gráfico resume las independencias condicionales de la última ecuación:
Aproximación por cuadrícula
En el caso jerárquico, no se puede derivar la distribución posterior de manera
analítica pero si los parámetros e hiperparámetros toman un número finito de
valores y no hay muchos de ellos, podemos aproximar la posterior usando
aproximación por cuadrícula.
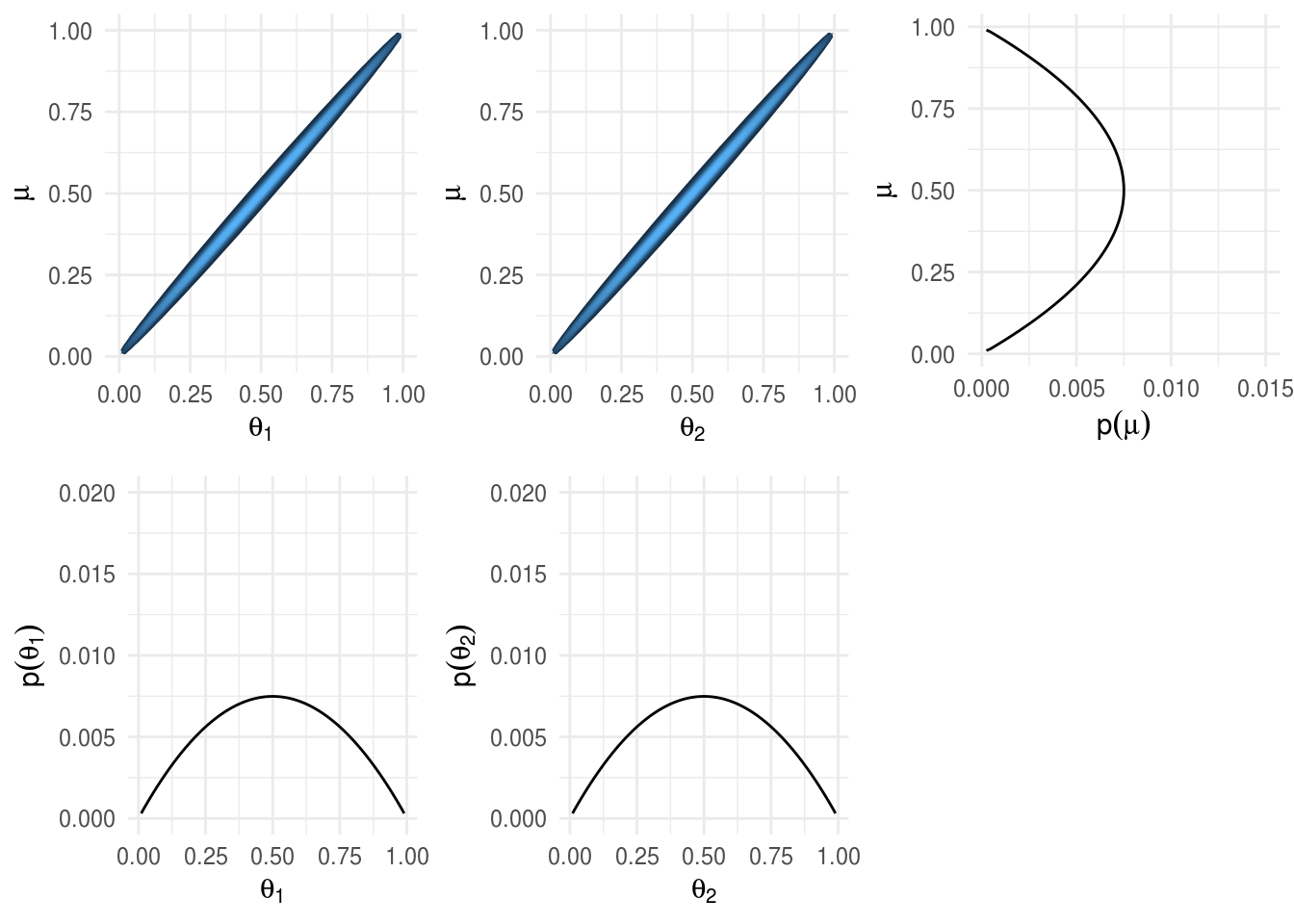
A continuación graficamos las distribuciones correspondientes al caso en que la distribución del hiperparámetro \(\mu\) tiene la forma de una distribución \(Beta(2, 2)\), es decir creemos que la media de la acuñadora \(\mu\) es \(0.5\), pero existe bastante incertidumbre acerca del valor.
La distribución de \(\theta\), esto es la distribución inicial que refleja la dependencia entre \(\theta\) y \(\mu\) se expresa por medio de otra distribución beta, en el ejemplo usamos \(K=100\):
\[\theta|\mu \sim beta(\mu 100, (1-\mu)100)\]
Esta inicial expresa un alto grado de certeza que una acuñadora con hiperparámetro \(\mu\) genera monedas con sesgo cercano a \(\mu\)
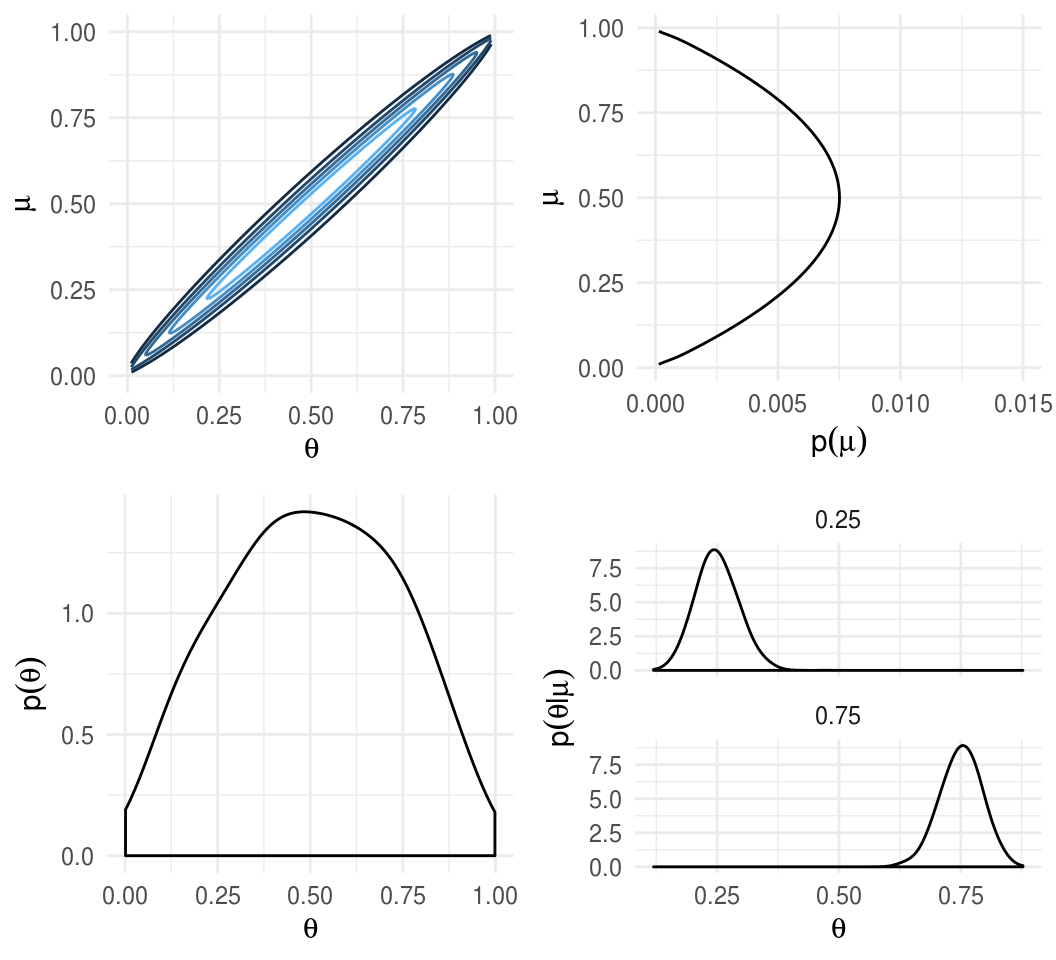
Verosimilitud.
Posterior.
Multiples monedas de una misma fábrica
La sección anterior considera el escenario en que lanzamos una moneda y hacemos inferencia del parámetro de sesgo \(\theta\) y del hiperparámetro \(\mu\). Ahora consideramos recolectar información de múltiples monedas, si cada moneda tiene su propio sesgo \(\theta_j\) entonces debemos estimar un parámetro distinto para cada moneda.
Suponemos que todas las monedas provienen de la misma fábrica, esto implica que tenemos la misma información inicial \(\mu\) para todas las monedas. Suponemos también que cada moneda se acuña de manera independiente, esto es, que condicional al parámetro \(\mu\) los parámetros \(\theta_j\) son independientes en nuestros conocimientos iniciales.
Posterior vía aproximación por cuadrícula
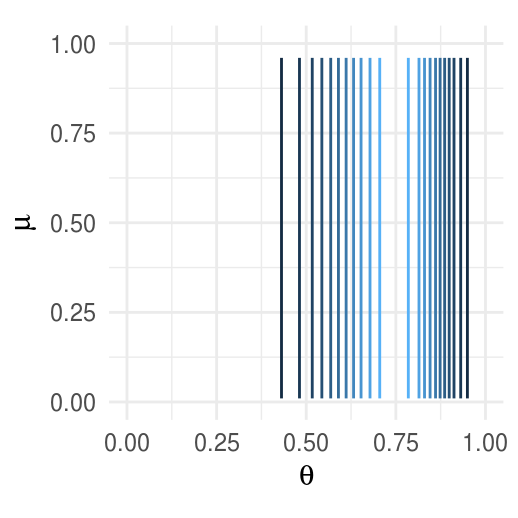
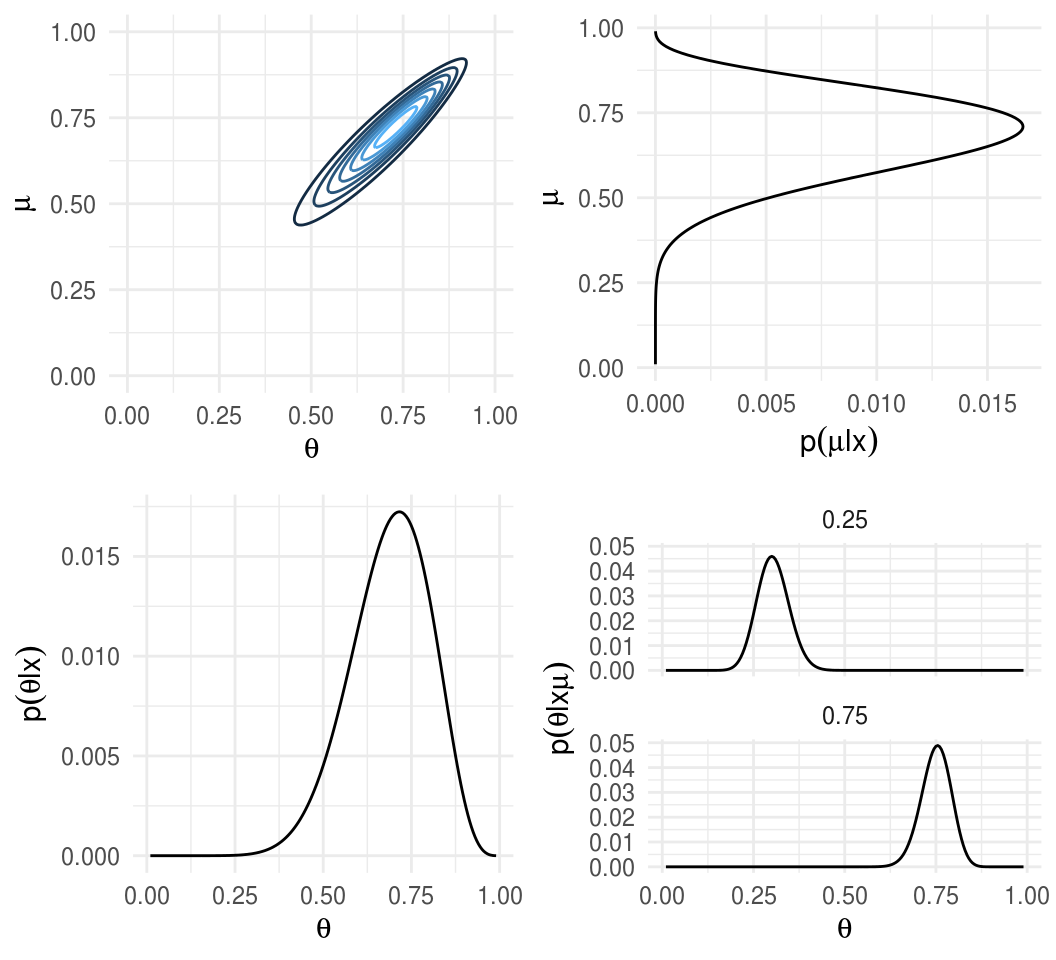
Supongamosque tenemos dos monedas de la misma fábrica. El objetivo es estimar los sesgos \(\theta_1\), \(\theta_2\) de las dos monedas y estimar simultáneamente el parámetro \(\mu\) correspondiente a la casa de moneda que las fabricó.
Inicial.
Verosimilitud.
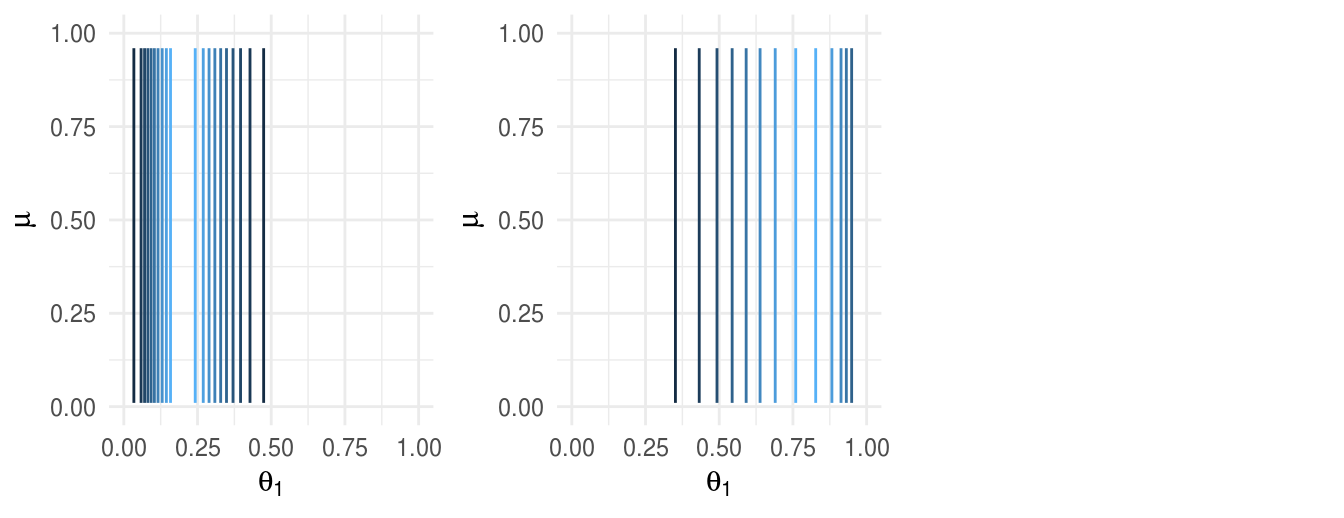
Posterior.
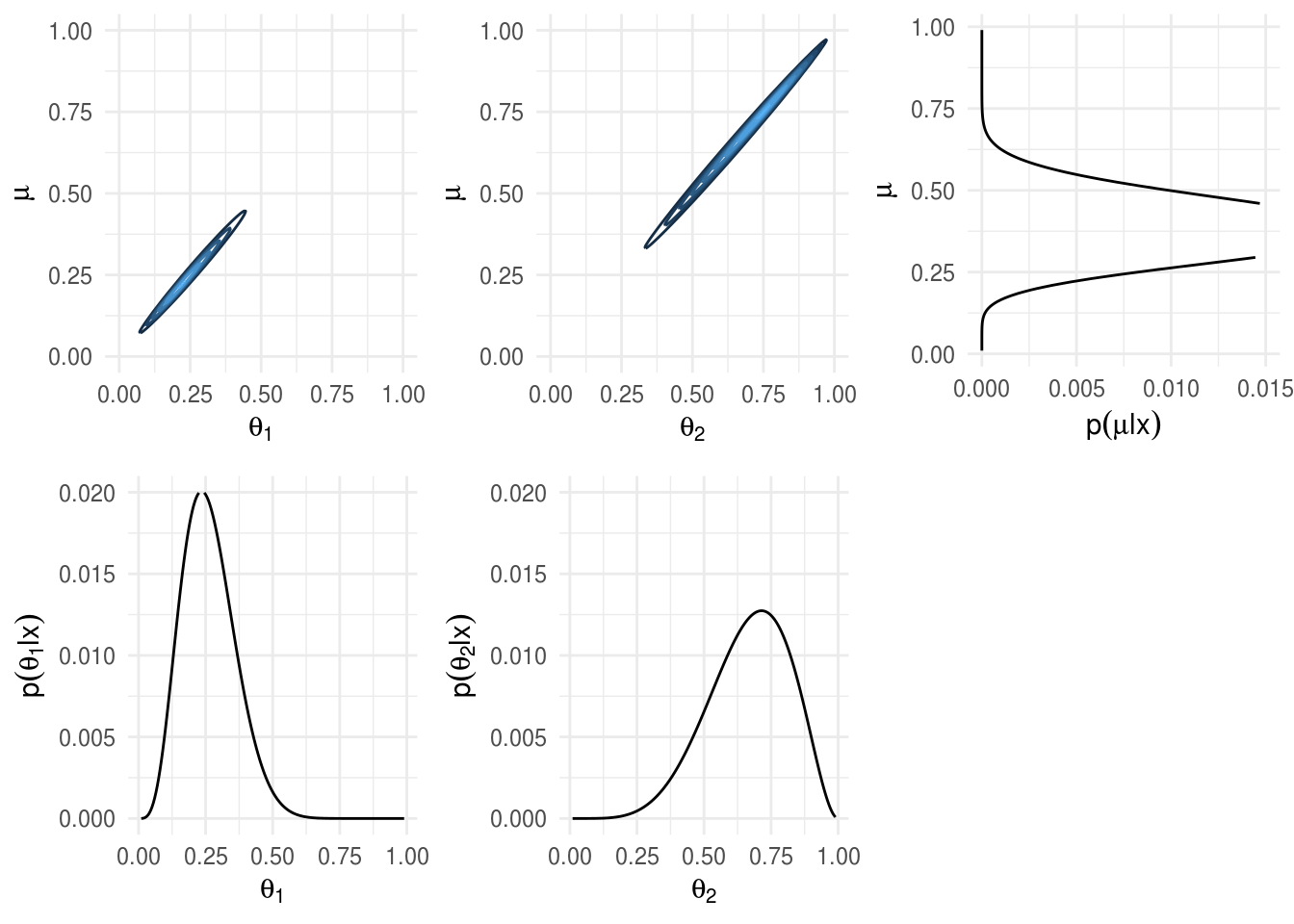
JAGS
La sección anterior utilizó un modelo simplificado con el objetivo de poder visualizar el espacio de parámetros. Ahora incluiremos más parámetros para hacer el problema más realista. En los ejemplos anteriores fijamos el grado de dependencia entre \(\mu\) y \(\theta\) de manera arbitraria, a través de \(K\), de tal manera que si \(K\) era grande, los valores \(\theta_j\) individuales se situaban cerca de \(\mu\) y cuando \(K\) era pequeña se permitía más variación.
En situaciones reales no conocemos el valor de \(K\) por adelantado, por lo que dejamos que los datos nos informen acerca de valores creíbles para \(K\). Intuitivamente, cuando la proporción de águilas observadas es similar a lo largo de las monedas, tenemos evidencia de que \(K\) es grande, mientras que si estas proporciones difieren mucho, tenemos evidencia de que \(K\) es pequeña. Debido a que \(K\) pasará de ser una constante a ser un parámetro lo llamaremos \(\kappa\).
La distribución inicial para \(\kappa\) será una Gamma.
modelo_jer.bugs <-
'
model{
for(t in 1:N){
x[t] ~ dbern(theta[coin[t]])
}
for(j in 1:nCoins){
theta[j] ~ dbeta(a, b)
}
a <- mu * kappa
b <- (1 - mu) * kappa
# A_mu = 2, B_mu = 2
mu ~ dbeta(2, 2)
kappa ~ dgamma(1, 0.1)
}
'\(\kappa \sim Gamma(1, 0.1)\), esta tiene media \(10\) y desviación estándar \(10\).
Los datos consisten en \(5\) monedas, cada una se lanza \(5\) veces, resultando \(4\) de ellas en \(1\) águila y \(4\) soles y otra en \(3\) águilas y \(2\) soles.
cat(modelo_jer.bugs, file = 'modelo_jer.bugs')
x <- c(0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1)
coin <- c(rep(1, 5), rep(2, 5), rep(3, 5), rep(4, 5), rep(5, 5))
jags.inits <- function(){
list("mu" = runif(1, 0.1, 0.9),
"kappa" = runif(1, 5, 20))
}
jags_fit <- jags(
model.file = "modelo_jer.bugs", # modelo de JAGS
inits = jags.inits, # valores iniciales
data = list(x = x, coin = coin, nCoins = 5, N = 25), # lista con los datos
parameters.to.save = c("mu", "kappa", "theta"), # parámetros por guardar
n.chains = 3, # número de cadenas
n.iter = 10000, # número de pasos
n.burnin = 1000 # calentamiento de la cadena
)
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 25
#> Unobserved stochastic nodes: 7
#> Total graph size: 65
#>
#> Initializing model
# R2jags::traceplot(jags_fit, varname = c("kappa", "mu", "theta"))
jags_fit
#> Inference for Bugs model at "modelo_jer.bugs", fit using jags,
#> 3 chains, each with 10000 iterations (first 1000 discarded), n.thin = 9
#> n.sims = 3000 iterations saved
#> mu.vect sd.vect 2.5% 25% 50% 75% 97.5% Rhat n.eff
#> kappa 14.213 10.626 2.128 6.483 11.385 19.053 42.222 1 2100
#> mu 0.330 0.098 0.156 0.263 0.323 0.395 0.538 1 3000
#> theta[1] 0.286 0.128 0.065 0.191 0.278 0.370 0.561 1 1400
#> theta[2] 0.286 0.130 0.067 0.192 0.277 0.368 0.567 1 3000
#> theta[3] 0.283 0.128 0.069 0.189 0.271 0.364 0.573 1 1300
#> theta[4] 0.283 0.129 0.066 0.185 0.273 0.365 0.557 1 1200
#> theta[5] 0.417 0.146 0.167 0.311 0.406 0.512 0.731 1 3000
#> deviance 30.318 2.102 27.521 28.803 29.924 31.329 35.603 1 2900
#>
#> For each parameter, n.eff is a crude measure of effective sample size,
#> and Rhat is the potential scale reduction factor (at convergence, Rhat=1).
#>
#> DIC info (using the rule, pD = var(deviance)/2)
#> pD = 2.2 and DIC = 32.5
#> DIC is an estimate of expected predictive error (lower deviance is better).sims_df <- data.frame(n_sim = 1:jags_fit$BUGSoutput$n.sims,
jags_fit$BUGSoutput$sims.matrix) %>%
dplyr::select(-deviance) %>%
gather(parametro, value, -n_sim)
ggplot(filter(sims_df, parametro != "kappa"), aes(x = value)) +
geom_histogram(alpha = 0.8) + facet_wrap(~ parametro)
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.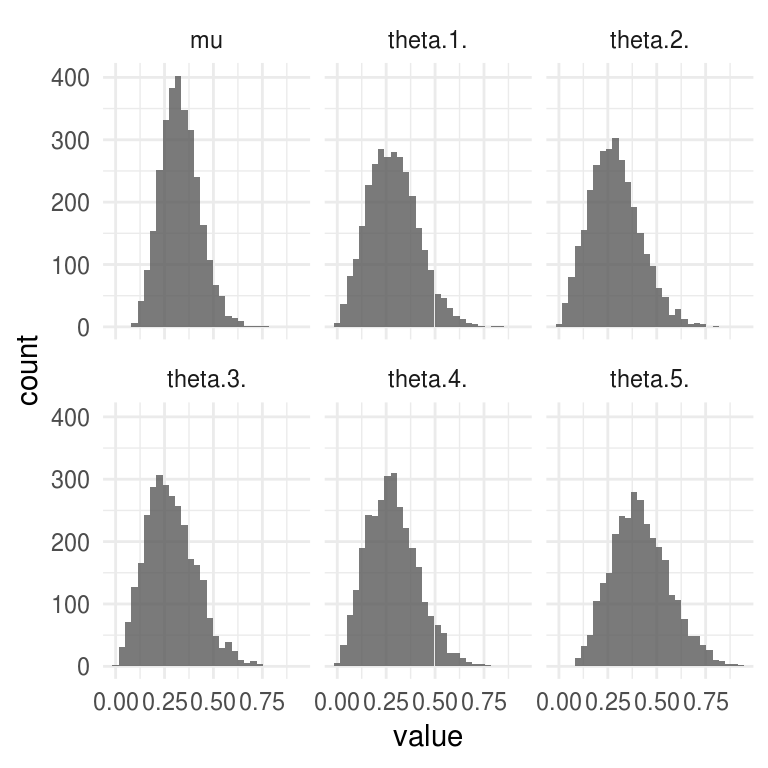
ggplot(filter(sims_df, parametro == "kappa"), aes(x = value)) +
geom_histogram(alpha = 0.8)
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.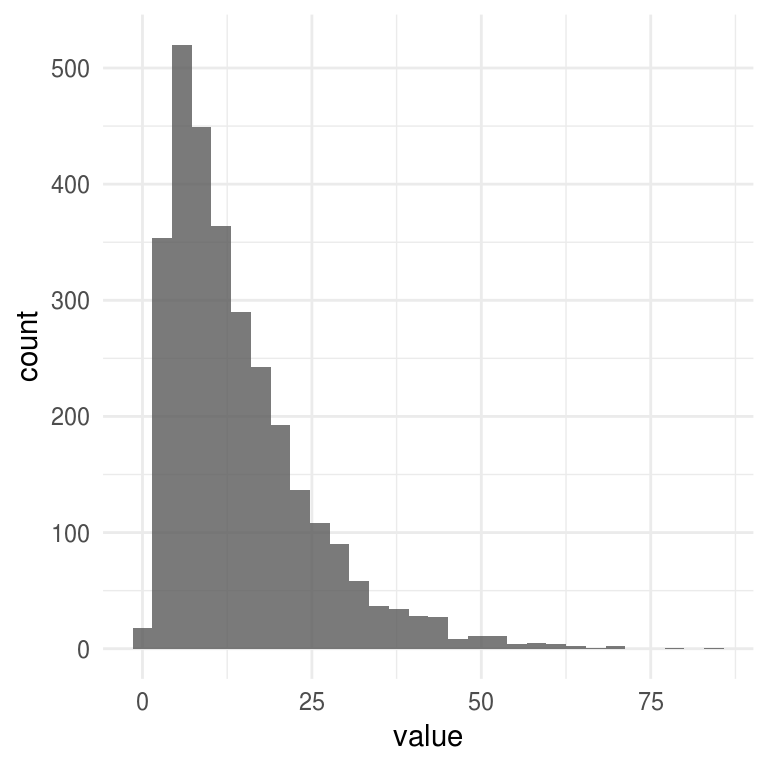
Stan
library(rstan)
modelo_jer.stan <-
'
data {
int N;
int x[N];
int nCoins;
int coin[N];
}
parameters {
real<lower=0,upper=1> theta[nCoins];
real<lower=0,upper=1> mu;
real<lower=0> kappa;
}
transformed parameters {
real<lower=0> a;
real<lower=0> b;
a = mu*kappa;
b = (1-mu)*kappa;
}
model {
theta ~ beta(a,b);
x ~ bernoulli(theta[coin]);
mu ~ beta(2, 2);
kappa ~ gamma(1, 0.1);
}
'
cat(file = "modelo_jer.stan", modelo_jer.stan)
stan_jer_cpp <- stan_model("modelo_jer.stan")
stan_jer_fit <- sampling(stan_jer_cpp,
data = list(x = x, coin = coin, nCoins = 5, N = 25), chains = 2,
cores = 2, iter = 400, warmup = 100)summary_stan_jer_fit$summary
#> mean se_mean sd 2.5% 25% 50% 75% 97.5%
#> theta[1] 0.289 0.00766 0.1249 0.0744 0.200 0.274 0.368 0.575
#> theta[2] 0.292 0.00759 0.1293 0.0748 0.205 0.279 0.368 0.589
#> theta[3] 0.297 0.00708 0.1240 0.0734 0.216 0.285 0.373 0.564
#> theta[4] 0.298 0.00701 0.1264 0.0760 0.210 0.284 0.372 0.587
#> theta[5] 0.410 0.00804 0.1435 0.1634 0.325 0.394 0.494 0.745
#> mu 0.335 0.00631 0.0981 0.1780 0.264 0.327 0.393 0.551
#> kappa 15.668 0.80857 10.5208 3.0674 8.104 13.510 20.156 43.563
#> a 5.075 0.30200 3.5354 0.9544 2.648 4.173 6.478 14.273
#> b 10.592 0.55036 7.5108 1.7908 4.977 8.929 13.832 31.860
#> lp__ -21.812 0.18573 2.3505 -27.5118 -23.219 -21.436 -20.095 -18.483
#> n_eff Rhat
#> theta[1] 266 1.003
#> theta[2] 290 1.002
#> theta[3] 307 1.007
#> theta[4] 325 0.997
#> theta[5] 319 0.997
#> mu 241 1.004
#> kappa 169 0.999
#> a 137 1.002
#> b 186 1.000
#> lp__ 160 1.001Ejemplo: estimación de tasas de mortalidad
En esta sección veremos un problema de estimación de tasas de mortalidad, la referencia de este ejemplo es Albert (2009). Plantearemos \(3\) alternativas de modelación para resolver el problema: modelo de unidades iguales, modelo de unidades independientes y finalmente modelo jerárquico.
La base de datos tiene información de todas las cirugías de transplante de corazón llevadas a cabo en Estados Unidos en un periodo de \(24\) meses, entre octubre de \(1987\) y diciembre de \(1989\). Para cada uno de los \(131\) hospitales, se registró el número de cirugías de transplante de corazón, y el número de muertes durante los \(30\) días posteriores a la cirugía, \(y\). Además, se cuenta con una predicción de la probabilidad de muerte de cada paciente individual. Esta predicción esta basada en un modelo logístico que incluye información a nivel paciente como condición médica antes de la cirugía, género, sexo y raza. En cada hospital se suman las probabilidades de muerte de sus pacientes para calcular el número esperado de muertes, \(e\), conocido como la exposición del hospital; \(e\) refleja el riesgo de muerte debido a la mezcla de pacientes que componen un hospital particular.
La matriz de datos que analizaremos considera únicamente los \(94\) hospitales que llevaron a cabo \(10\) o más cirugías, y consiste en las duplas \((y_{j}, e_{j})\) que corresponden al número observado de muertes y número de expuestos para el \(j\)-ésimo hospital, con \(j = 1,...,94\).
library(LearnBayes)
data(hearttransplants)
heart <- hearttransplants %>%
mutate(hospital = 1:n())
head(heart)
#> e y hospital
#> 1 532 0 1
#> 2 584 0 2
#> 3 672 2 3
#> 4 722 1 4
#> 5 904 1 5
#> 6 1236 0 6El objetivo es obtener buenas estimaciones de las tasas de mortalidad de cada hospital. Antes de comenzar a ajustar modelos complejos vale la pena observar los datos. El cociente \(\{y_{j}/e_{j}\}\) es el número observado de muertes por unidad de exposición y se puede ver como una estimación de la tasa de mortalidad. La siguiente figura grafica, en el eje vertical los cocientes \(\{y_{j}/e_{j}\}\) multiplicados por \(1000\) (con la intención de que la tasa indique número de muertes por \(1000\) expuestos), y en el eje horizontal el número de expuestos \(\{e_{j}\}\) -en escala logarítmica- para los \(94\) hospitales. Cada punto representa un hospital y esta etiquetado con el número de muertes observadas \(\{y_{j}\}\). En la gráfica podemos notar que las tasas estimadas son muy variables, especialmente para programas con baja exposición. Observemos también, que la mayoría de los programas que no experimentaron muertes tienen bajo número de expuestos.
ggplot(heart, aes(x = log(e), y = 1000* y / e, color = factor(y), label = y)) +
geom_text(show.legend = FALSE) +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) 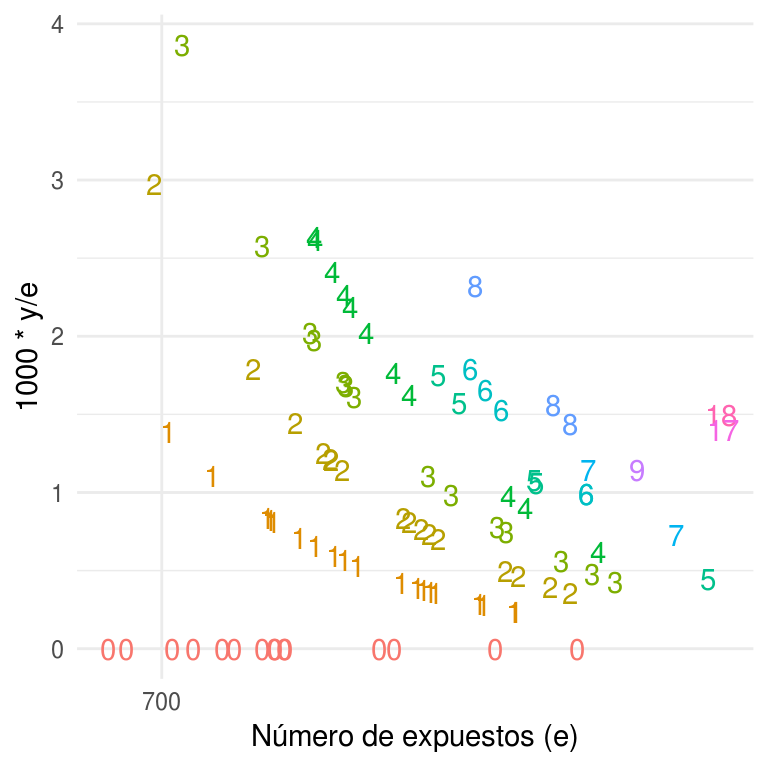
La variabilidad de las tasas y los hospitales sin muertes sugieren un problema de tamaño de muestra. Consideremos un hospital con \(700\) expuestos. La muerte por transplante de corazón no es común, el promedio nacional es de \(9\) por cada \(10,000\) expuestos, por lo que con \(700\) expuestos es probable que no se presente ninguna muerte, en este caso el hospital pertenece al \(10\%\) de los hospitales con menor tasa de mortalidad. Sin embargo, existe la posibilidad de que se observe una muerte, con lo cual el hospital tendrá una tasa de mortalidad que es lo suficientemente alta para que quede en el \(25\%\) de los hospitales con mayor tasa de mortalidad observada.
Una vez reconocido el problema de utilizar los datos crudos para estimar las tasas de mortalidad plantearemos \(3\) alternativas de modelación:
- Unidades iguales. Considera que los estudios son replicas idénticas una de otra, en este sentido vemos a las observaciones de todos los estudios como muestras independientes de una misma población y consecuentemente todas las \(\lambda_{j}\) se consideran iguales,
\[ \begin{eqnarray} \nonumber y_{j} &\sim& f(y_{j}|\lambda),\\ \nonumber \lambda &\sim& g(\lambda). \end{eqnarray} \] El modelo gráfico correspondiente a este enfoque (omitiendo la distribución de \(\lambda\)) es:
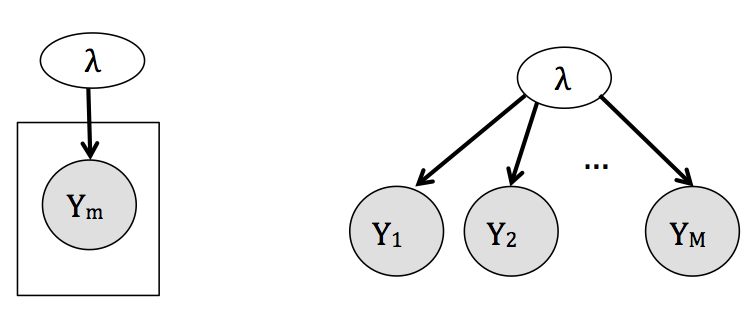
- Unidades independientes. El extremo opuesto a unidades iguales considera que los estudios son tan diferentes que los resultados de cada uno no proveen información acerca de los resultados de ningún otro y por tanto realizamos estimaciones individuales para cada \(\lambda_{j}\), \[ \begin{align} \nonumber y_{j} &\sim f(y_{j}|\lambda_{j}),\\ \nonumber \lambda_j &\stackrel{\mathrm{iid}}{\sim} g(\lambda_j). \end{align} \] Con el siguiente modelo gráfico:
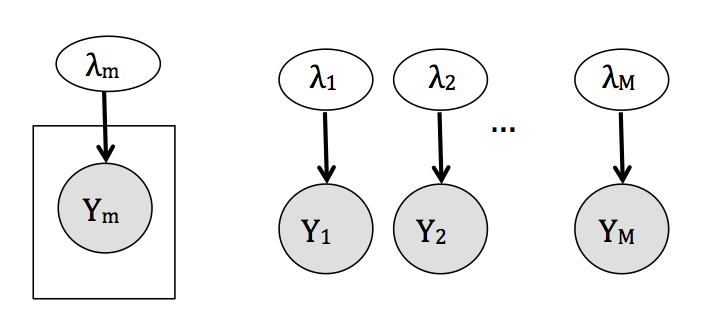
- Jerárquico. Es un análisis intermedio que considera los parámetros de interés \(\lambda_{j}\) como provenientes de una distribución común, \[ \begin{eqnarray} \nonumber y_{j} &\sim& f(y_{j}|\lambda_{j}),\\ \nonumber \lambda_{j} &\sim& g(\lambda_j|\theta),\\ \theta &\sim& h(\theta). \end{eqnarray} \]
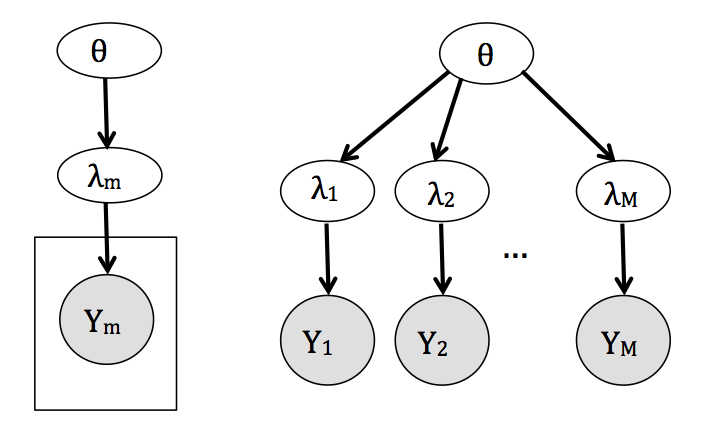
De esta manera, la probabilidad conjunta del modelo refleja una dependencia
entre los parámetros al mismo tiempo que permite variaciones entre los estudios.
Como resultado se estima una \(\lambda_{j}\) diferente para cada estudio usando
información de todos.
Notemos que la estructura del modelo jerárquico facilita la implementación del muestreador de Gibbs debido a que es inmediato factorizar la conjunta en
condicionales completas.
10.11.0.1 Modelo de unidades iguales
Supongamos que las tasas de mortalidad son iguales a lo largo de los hospitales. Estimaremos la tasa de mortalidad con el modelo,
\[ \begin{eqnarray} \nonumber y_{j} \sim Poisson(e_{j}\lambda), \end{eqnarray} \]
donde \(y_{j}\) es el número de muertes observadas por transplante corazón en el hospital \(j\), \(e_{j}\) es el número de expuestos, y \(\lambda\) es la tasa de mortalidad, medida en número de muertes por unidad de exposción y común para todos los hospitales.
Debido a que no contamos con información inicial acerca de la tasa de mortalidad, asignamos a \(\lambda\) una distribución inicial no informativa, de la forma
\[ \begin{eqnarray} \nonumber g(\lambda)\propto\frac{1}{\lambda}. \end{eqnarray} \]
Sea \(y=(y_1,...,y_{94})\), usamos el Teorema de Bayes para calcular la densidad posterior de \(\lambda\),
\[ \begin{eqnarray} \nonumber g(\lambda|y) &\propto& g(\lambda)f(y|\lambda) \\ \nonumber &=& g(\lambda)\prod_{i=1}^{94}f(y_{i}|\lambda)\\ \nonumber &=& \frac{1}{\lambda}\prod_{i=1}^{94}\bigg(\frac{exp(-e_{i}\lambda)(e_{i}\lambda)^{y_{i}}}{y_{i}!}\bigg)\\ \nonumber &\propto& \lambda^{(\sum_{i=1}^{94}y_{j}-1)}exp\bigg(-\sum_{i=1}^{94}e_{j}\lambda\bigg), \end{eqnarray} \] identificamos la densidad posterior como una \(Gamma(\sum_{i=1}^{94}y_{i},\sum_{i=1}^{94}e_{i})\), donde expresamos la función de densidad de una distribución \(Gamma(\alpha, \beta)\) usando el parámetro de forma \(\alpha\) y el inverso del parámetro de escala \(\beta\) de manera que la función de densidad es,
\[ \begin{align} \nonumber &f(x|\alpha, \beta) = \beta^{\alpha}\frac{1}{\Gamma(\alpha)}x^{\alpha-1}e^{-\beta x}I_{(0,\infty)}(x)\\ \nonumber &\mbox{para }x \geq 0 \mbox{ y }\alpha \mbox{, }\beta > 0. \end{align} \]
Para verificar el ajuste del modelo utilizaremos la distribución predictiva posterior. Denotemos \(y_{j}^*\) el número de muertes por transplante en el hospital \(j\) con exposición \(e_{j}\) en una muestra futura. Condicional a \(\lambda\), \(y_{j}^*\) se distribuye \(Poisson(e_{j}\lambda)\), no conocemos el verdadero valor de \(\lambda\), sin embargo nuestro conocimiento actual está contenido en la densidad posterior \(g(\lambda|y)\). Por tanto, la distribución predictiva posterior de \(y_{j}^*\) esta dada por:
\[ \begin{eqnarray} \nonumber f(y_{j}^*|e_{j},y) = \int f(y_{j}^*|e_{j}\lambda)g(\lambda|y)d\lambda, \end{eqnarray} \]
donde \(f(y_j^*|e_{j}\lambda)\) es una densidad Poisson con media \(\lambda\). La densidad predictiva posterior representa la verosimilitud de observaciones futuras basadas en el modelo ajustado. En este ejemplo, la densidad \(f(y_{j}^*|e_{j},y)\) representa el número de transplantes que se predecirían para un hospital con exposición \(e_{j}\). Entonces, si el número observado de muertes \(y_{j}\) no está en las colas de la distribución predictiva, diríamos que la observación es consistente con el modelo observado.
# La densidad posterior es Gamma con los siguientes parámetros
c(sum(heart$y), sum(heart$e))
#> [1] 277 294681
# Simulamos 1000 muestras de la densidad posterior de lambda
lambdas <- rgamma(1000, shape = sum(heart$y), rate = sum(heart$e))
# ahora para cada hospital simulamos muestras de una distribución Poisson
# con media e_i*lambda
heart_sims <- heart %>%
mutate(sims = map(e, ~rpois(1000, . * lambdas)))
# tomamos una muestra de 10 hospitales
set.seed(242)
heart_sims_sample <- sample_n(heart_sims, 10)
ggplot(unnest(heart_sims_sample), aes(x = sims)) +
geom_histogram(aes(y = ..density..), binwidth = 1, color = "darkgray",
fill = "darkgray") +
facet_wrap(~ hospital, nrow = 2) +
geom_segment(data = heart_sims_sample, aes(x = y, xend = y, y = 0,
yend = 0.5),
color = "red") +
geom_text(data= heart_sims_sample, aes(x = 10, y = 0.4,
label = paste("e =", e)), size = 2.7, color = "red")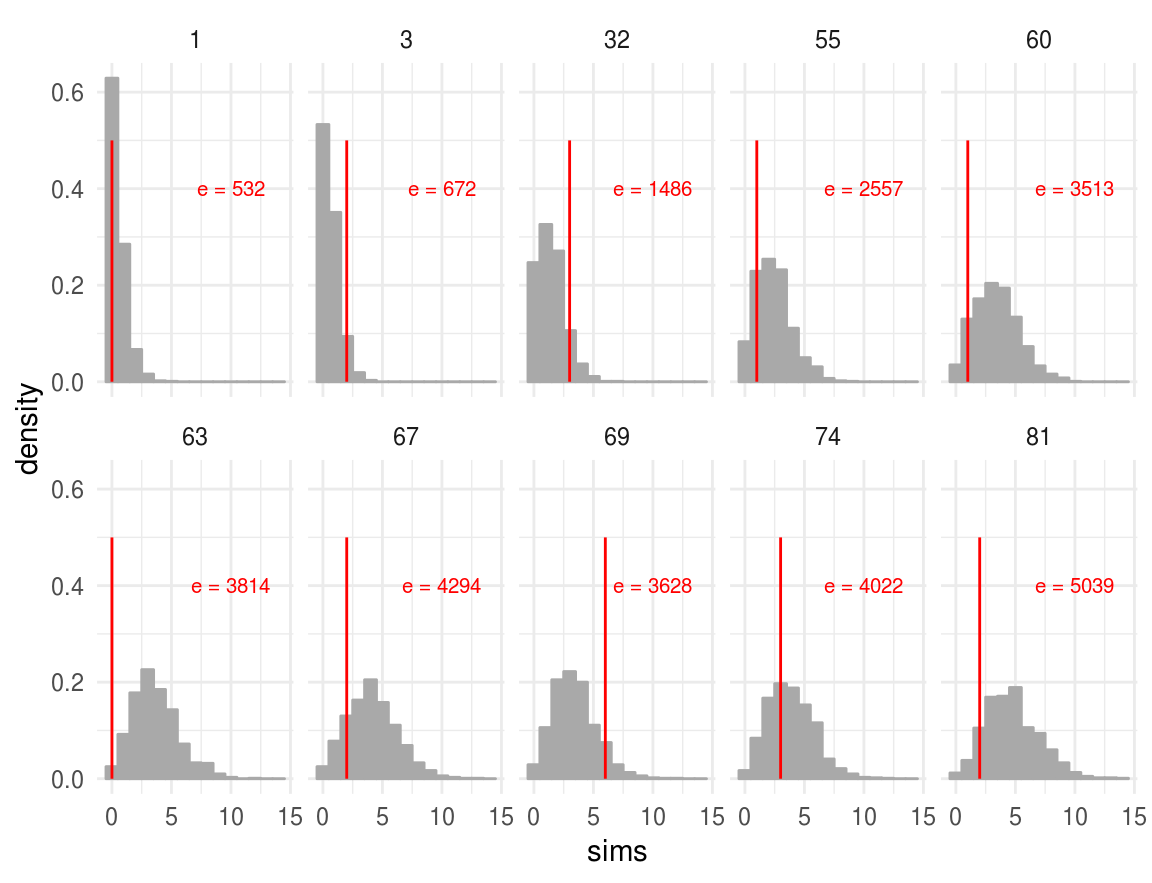
La figura muestra los histogramas, obtenidos con simulación, de la distribución predictiva posterior de \(10\) hospitales (se tomó una muestra de los \(94\)). Para cada hospital, se escribió el número de expuestos, \(e\), y se grafica una línea vertical en el número de muertes observado. Notemos que en muchos de los histogramas el número de muertes observado se encuentra en las colas de las distribuciones, lo que sugiere que nuestras observaciones son inconsistentes con el modelo ajustado.
Ahora examinaremos la consistencia de las muertes observadas, \(y_{j}\), para todos los hospitales. Para cada distribución predictiva posterior calculamos la probabilidad de que una observación futura \(y_{j}^*\) sea al menos tan extrema como \(y_{j}\), estas probabilidades son comúnmente llamadas valores \(p\) predictivos:
\[ \begin{eqnarray} \nonumber P(extremos) = min\{P(y_{j}^* \leq y_{j}),P(y_{j}^*\geq y_{j})\} \end{eqnarray} \]
# Para calcular las p predictiva podemos usar las simulaciones
p_pred <- heart_sims %>%
unnest() %>%
group_by(hospital) %>%
summarise(
p = min(sum(sims <= y) / 1000, sum(sims >= y) / 1000),
e = first(e)
)
ggplot(p_pred, aes(x = log(e), y = p)) +
geom_point() +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
ylab("P(extremos)") +
geom_hline(yintercept = .15, colour = "red", size = 0.4) +
ylim(0, .7) 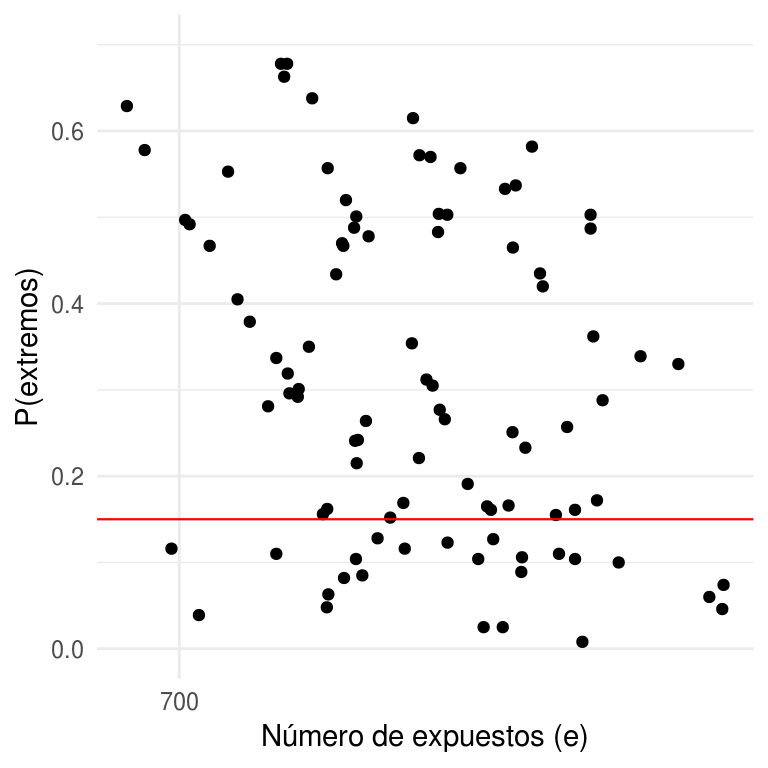
En la figura anterior graficamos las probabilidades de extremos (calculadas con simulación) en el eje vertical, contra el número de exposición en escala logarítmica de cada hospital en el eje horizontal. Notemos que muchas de estas probabilidades son pequeñas, el \(28\%\) son menores a \(0.15\), lo que indica que para el \(28\%\) de los hospitales el número de muertes observado \(y_{j}\) está en la cola de la distribución y por consiguiente el modelo es inadecuado.
Modelo de unidades independientes
Consideremos ahora que los hospitales son independientes, estimaremos la tasa de mortalidad para cada hospital con el modelo
\[ \begin{eqnarray} \nonumber y_{j}\sim Poisson(e_{j}\lambda_{j}), \end{eqnarray} \]
donde \(y_{j}\) es el número de muertes observadas por transplante corazón en el hospital \(j\), \(e_{j}\) es el número de expuestos, y \(\lambda_{j}\) es la tasa de mortalidad, medida en número de muertes por unidad de exposición, con \(j=1,...,94\). Utilizamos el subíndice \(j\) para enfatizar que son parámetros diferentes, cada uno estimado con sus propios datos.
Por facilidad asignamos a \(\lambda_{j}\) una distribución inicial \(Gamma(\alpha_{0}, \beta_{0})\) que es conjugada de la distribución Poisson,
\[ \begin{eqnarray} \nonumber g(\lambda_{j}|\alpha_{0},\beta_{0}) = \frac{\beta_{0}^{\alpha_{0}} \lambda_{j}^{\alpha_{0}-1}exp(-\lambda_{j} \beta_{0})}{\Gamma(\alpha_{0})}, \lambda_{j}>0. \end{eqnarray} \]
Calculamos la densidad posterior de \(\lambda_{j}\) usando el Teorema de Bayes,
\[ \begin{eqnarray} \nonumber g(\lambda_{j}|y_{j},\alpha_{0},\beta_{0}) &\propto& g(\lambda_{j}|\alpha_{0},\beta_{0})f(y_{j}|\lambda_{j})\\ \nonumber &=& \frac{\beta_{0}^{\alpha_{0}} \lambda_{j}^{\alpha_{0}-1}exp(-\lambda_{j} \beta_{0})}{\Gamma(\alpha_{0})}\frac{exp(-e_{j}\lambda_{j})(e_{j}\lambda_{j})^{y_{j}}}{y_{j}!}\\ \nonumber &\propto& \lambda_{j}^{\alpha_{0}+y_{j}-1}exp(-\lambda_{j}(\beta_{0}+e_{j})), \end{eqnarray} \]
y obtenemos que \(\lambda_{j}|y_{j} \sim Gamma(\alpha_{0}+y_{j}, \beta_{0}+e_{j})\), con media
\[ \begin{eqnarray} \nonumber E(\lambda_{j}|y_{j},\alpha_{0},\beta_{0}) &=& \frac{\alpha_{0}+y_{j}}{\beta_{0}+e_{j}}\\ \label{eqn:pond.indep} &=& (1-A_{j})\frac{y_{j}}{e_{j}}+A_{j}\frac{\alpha_{0}}{\beta_{0}} \end{eqnarray} \]
donde
\[ \begin{eqnarray} A_{j}=\frac{\beta_{0}}{\beta_{0}+e_{j}}, \end{eqnarray} \] y varianza
\[ \begin{eqnarray} \nonumber Var(\lambda_{j} |y_{j},\alpha_{0},\beta_{0}) = \frac{\alpha_{0}+y_{j}}{(\beta_{0}+e_{j})^2}. \end{eqnarray} \]
Notemos que podemos escribir la media posterior como un promedio ponderado de la tasa observada \(y_{j}/e_{j}\) y la media inicial \(\alpha_{0} / \beta_{0}\). El factor \(A_{j}\) es el encogimiento hacia la media inicial y depende del número de exposición de cada hospital y del parámetro de escala \(\beta_{0}\).
Efecto de \({\beta_{0}}\) y \({e_{j}}\) en la distribución posterior
Consideremos la media y varianza posteriores de \(\lambda_{j}\) para un hospital particular. Tomando \(\alpha_{0}\) fija, valores mayores de \(\beta_{0}\) corresponden a una menor varianza en la distribución inicial pues \(Var(\lambda_{j} | \alpha_{0},\beta_{0}) = \alpha_{0}/\beta_{0}^2\). La varianza de la distribución inicial se refleja en la media de la distribución posterior de \(\lambda_{j}\) a través de \(\beta_{0}\), menor varianza (mayor \(\beta_{0}\)) corresponde a mayor encogimineto hacia la media inicial. Este efecto de \(\beta_{0}\) concuerda con la incertidumbre de nuestro conocimiento, pues menor varianza en la distribución inicial indica menor incertidumbre y la aportación de la media inicial a la media posterior es más importante. La elección de \(\beta_{0}\) también afecta la varianza, pues un menor valor de \(\beta_{0}\) implica una mayor varianza tanto en la distribución inicial como en la final.
Por su parte, tomando \(\alpha_{0}\) y \(\beta_{0}\) fijas, el efecto del número de expuestos \(e_{j}\) sobre la media posterior de \(\lambda_{j}\) actúa de manera contraria a \(\beta_{0}\). Un mayor número de expuestos tiene como consecuencia un menor encogimiento hacia la media inicial, dando mayor importancia a la tasa observada \(y_{j}/e_{j}\). Esto refleja que más expuestos implican más información proveniente de la muestra, restando importancia a nuestro conocimiento inicial. En cuanto a la varianza posterior, es inversamente proporcional al número de expuestos indicando nuevamente que más expuestos implica más conocimiento y por tanto menor incertidumbre.
En la siguiente fugura mostraremos el encogimiento hacia la media inicial bajo distintos escenarios de \(\beta_{0}\), cada punto representa un hospital y el color indica a que valor de \(\beta_{0}\) corresponde. En esta gráfica podemos apreciar el mayor encogimiento para valores mayores de \(\beta_{0}\) y el decaimiento en el encogimiento conforme aumenta el número de expuestos.
heart_indep <- heart %>%
crossing(beta_0 = c(1000, 100, 10, 0.01)) %>%
mutate(encogimiento = beta_0 / (beta_0 + e))
glimpse(heart_indep)
#> Observations: 376
#> Variables: 5
#> $ e <int> 532, 532, 532, 532, 584, 584, 584, 584, 672, 672,...
#> $ y <int> 0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2, 1, 1, 1, 1, 1...
#> $ hospital <int> 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5...
#> $ beta_0 <dbl> 1e-02, 1e+01, 1e+02, 1e+03, 1e-02, 1e+01, 1e+02, ...
#> $ encogimiento <dbl> 1.88e-05, 1.85e-02, 1.58e-01, 6.53e-01, 1.71e-05,...
ggplot(heart_indep, aes(x = log(e), y = encogimiento,
color = factor(beta_0))) +
geom_point(alpha = 0.9) +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
scale_color_hue(expression(beta[0])) +
ylab("encogimiento (A)")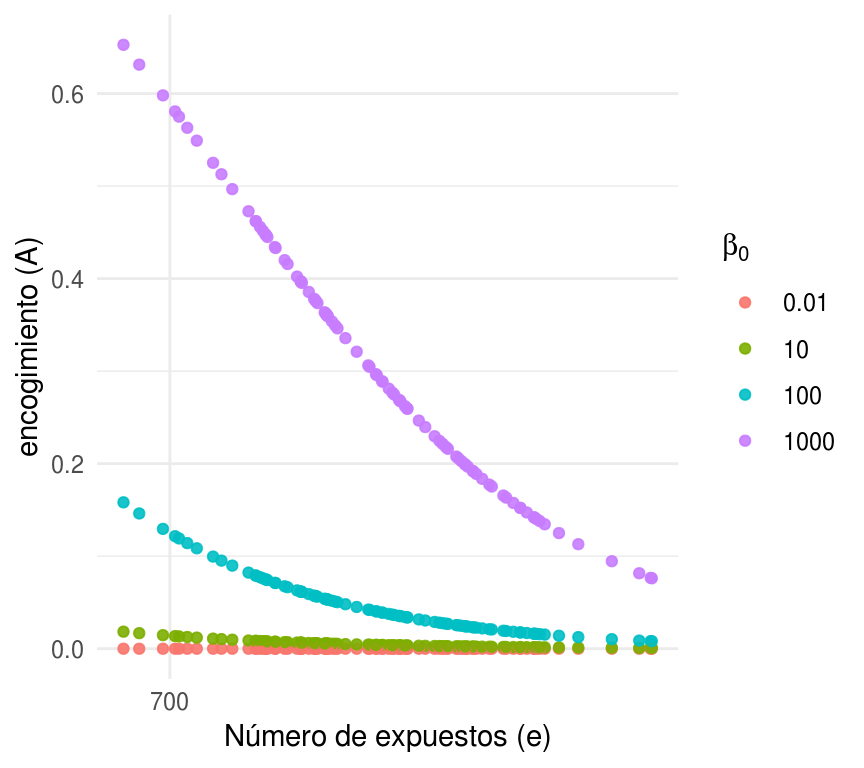
Distribución inicial
Establecimos que por facilidad se utilizará una inicial \(Gamma(\alpha_{0},\beta_{0})\), sin embargo hace falta asignar valores a los parámetros iniciales. Analizaremos \(3\) distintas combinaciones de parámetros iniciales y su efecto en las estimaciones posteriores.
Para cada combinación de parámetros la siguiente tabla muestra los deciles de \(2000\) simulaciones de una distribución \(Gamma(\alpha_0,\beta_{0})\) y los deciles de las muertes observadas por cada \(1000\) expuestos considerando todos los hospitales; multiplicamos las simulaciones por \(1000\) para que indiquen tasas de mortalidad medidas en número de muertes por \(1000\) expuestos. El propósito de la tabla es describir la forma de la distribución \(Gamma\) al cambiar los parámetros, por ejemplo, una \(Gamma(0.01,0.01)\) es muy plana y podríamos describirla como poco informativa, mientras que una \(Gamma(1,1000)\) tiene una forma más cercana a las tasas de mortalidad observadas.
| decil | \((0.01,0.01)\) | \((0.5,0.01)\) | \((1,1000)\) | Observados |
|---|---|---|---|---|
| min | 0 | 0 | 0 | 0 |
| 10 | 0 | 890.3 | 0.1 | 0 |
| 20 | 0 | 3134.7 | 0.2 | 0.3 |
| 30 | 0 | 7769.0 | 0.3 | 0.5 |
| 40 | 0 | 15036.0 | 0.5 | 0.7 |
| 50 | 0 | 24293.9 | 0.7 | 0.8 |
| 60 | 0 | 37306.0 | 0.9 | 1.1 |
| 70 | 0 | 57640.2 | 1.2 | 1.4 |
| 80 | 0 | 84255.5 | 1.6 | 1.7 |
| 90 | 4.2 | 140721.9 | 2.3 | 2.0 |
| max | 287307.6 | 592073.2 | 7.0 | 3.9 |
Ahora realizamos una gráfica para cada pareja de parámetros
\((\alpha_0,\beta_{0})\) donde mostramos en negro las tasas observadas, y en color
las estimaciones posteriores de las tasas de mortalidad con intervalos del \(95\%\)
de probabilidad, ambas medidas en número de muertes por cada \(1000\) expuestos.
Cada punto representa un hospital y el color corresponde al número de muertes
observadas, \(\{y_{j}\}\). Regresaremos a esta gráfica más adelante pero por lo
pronto observemos que tanto las estimaciones como los intervalos de probabilidad
son muy diferentes al cambiar los parámetros de la distribución inicial.
# Procedemos como antes, para cada combinación de alfa y beta simulamos 1000
# lambdas de la posterior
lambdas <- rgamma(1000, shape = sum(heart$y), rate = sum(heart$e))
# ahora para cada hospital simulamos muestras de una distribución Poisson
# con media e_i*lambda
priors <- data_frame(alpha = c(0.01, 0.5, 1), beta = c(0.01, 0.01, 1000))
heart_indep_sims <- heart %>%
crossing(priors) %>%
mutate(
sims = pmap(list(e, y, alpha, beta), ~rgamma(1000, shape = ..3 + ..2,
rate = ..4 + ..1))
)
# Creamos intervalos con las simulaciones
heart_indep_post <- heart_indep_sims %>%
mutate(
media = 1000 * (alpha + y) / (beta + e),
int_l = map_dbl(sims, ~quantile(1000 * ., 0.025)),
int_u = map_dbl(sims, ~quantile(1000 * ., 0.975)),
params = paste0("alpha = ", alpha, ", beta = ", beta)
)
ggplot(heart_indep_post, aes(x = log(e), y = media, color = factor(y))) +
geom_pointrange(aes(ymin = int_l, ymax = int_u), size = 0.25) +
geom_point(data = heart, aes(x = log(e), y = 1000 * y / e), color = "black",
alpha = 0.6, size = 1.5) +
facet_wrap(~params, ncol = 1) +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
scale_colour_hue("muertes obs. (y)") +
ylab("Muertes por 1000 expuestos")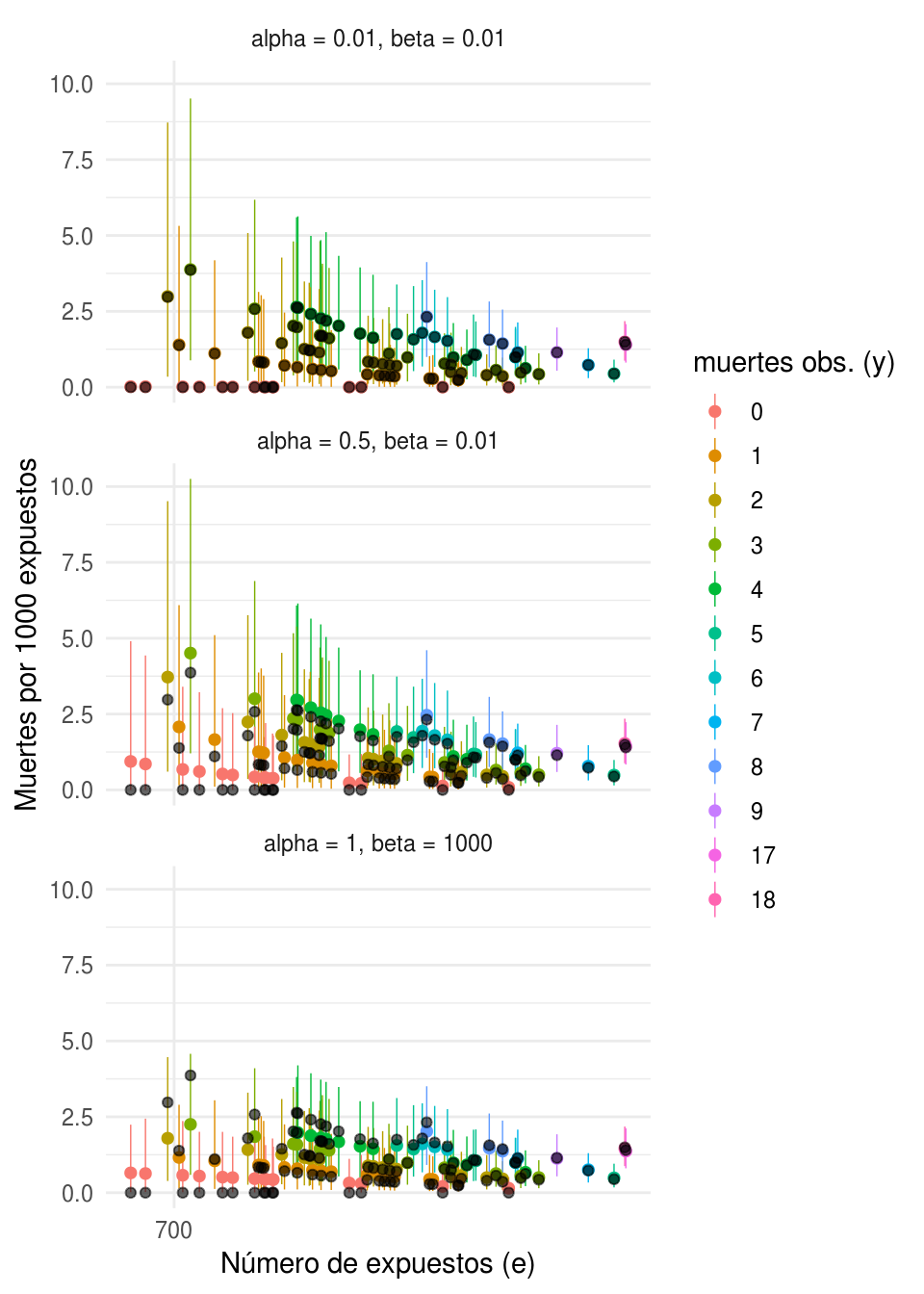
Ahora justificaremos la elección de las parejas de parámetros iniciales. La única información con la que contamos para definir una distribución inicial es que la tasa de mortalidad por transplante de corazón debe ser positiva y no muy grande. Debido a que no tenemos más información nuestro primer modelo utiliza una inicial vaga.
No informativas
Asignamos a \(\lambda_{j}\) una distribución inicial \(Gamma(0.01, 0.01)\). La tabla de deciles indica que es una distribución muy plana y si observamos la gráfica de encogimiento notamos que para una inicial con este valor en el parámetro de escala \(\beta_{0}\), el encogimiento de la media posterior hacia la media inicial es muy cercano a cero, dando poca importancia a la media inicial \(\alpha_{0}/\beta_{0}=1\). Como consecuencia, las estimaciones posteriores de \(\lambda_{j}\) son casi iguales a las tasas observadas \(\{y_{j}/e_{j}\}\), y se presentan los problemas de tamaño de muestra notados al usar las tasas observadas como estimaciones de las tasas de mortalidad. Además, los intervalos de confianza para los hospitales que no experimentaron muertes son poco creíbles pues son mucho más chicos que el resto.
La siguiente distribución inicial que consideramos es una \(Gamma(0.5,0.01)\). En este caso, la elección de los parámetros se basó en la distribución inicial no informativa de Jeffreys, consiste en una \(Gamma(0.5,0)\). Es una distribución impropia por lo que cambiamos el parámetro de escala por \(0.01\) para obtener una inicial propia con varianza grande. Los resultados no son muy razonables, pues la media inicial es \(50\), mucho mayor a las tasas observada para todos los hospitales, provocando que las estimaciones del modelo sean mayores a las tasas observadas en todos los hospitales. Este efecto es contrario al que buscábamos al usar una inicial vaga pues la distribución inicial tiene un impacto muy fuerte en las estimaciones posteriores.
Informativa
Finalmente, consideramos una distribución inicial \(Gamma(1,1000)\), ésta inicial es informativa. Para obtener sus parámetros igualamos los media y varianza teórica de la distribución \(Gamma\) con la media y varianza observadas en el conjunto de tasas de mortalidad tomando en cuenta todos los hospitales. Las estimaciones de las tasas de mortalidad que obtenemos parecen razonables, sin embargo, especificar la distribución inicial con la muestra tiene problemas lógicos y prácticos: 1) los datos se están usando \(2\) veces, primero la información de todos los hospitales se usa para especificar la distribución inicial, y después la información de cada hospital se usa para estimar su tasa de mortalidad \(\lambda_{j}\), lo que ocasiona que sobreestimemos nuestra precisión. 2) De acuerdo a la lógica bayesiana no tiene sentido estimar \(\alpha_{0}\) y \(\beta_{0}\), pues son parte de la distribución inicial y no deben depender de los datos.
A pesar de los problemas señalados parece ser conveniente intentar mejorar las
estimaciones individuales de \(\lambda_{j}\) usando la información de todos los
hospitales. La manera correcta de hacerlo es establecer un modelo de
probabilidad para todo el conjunto de parámetros
\(\{\alpha,\beta,\lambda_{1},...,\lambda_{94}\}\) y después realizar un análisis
de la distribución conjunta.
Se llevará a cabo un análisis completo en la siguiente sección en donde se usará
un modelo jerárquico.
Podemos concluir que el modelo de unidades independientes no es robusto para nuestros datos pues las estimaciones posteriores de las tasas de mortalidad son muy sensibles a la elección de los parámetros de la distribución inicial.
Modelo jerárquico
En este ejemplo se destaca el modelo jerárquico como una estrategia intermedia entre el modelo de unidades iguales y el modelo de unidades independientes. Nos permite reflejar un escenario en donde la información de cada estudio aporta información acerca del parámetro de interés \(\lambda_j\) de los demás estudios sin considerarlos idénticos, de manera que se estima un parámetro \(\lambda_j\) diferente para cada hospital.
Enumeramos algunas de las ventajas potenciales de usar un modelo jerárquico.
Modelo unificado. El problema de elegir entre un modelo de unidades iguales o uno de unidades independientes se resuelve al modelar explícitamente la variabilidad entre las unidades.
Unir fuerzas. Debido al supuesto de intercambiabilidad, al estimar el parámetro de cada unidad se usa información de las demás unidades, conllevando a un encogimiento de la estimación individual hacia la media poblacional, y resulta en una mejor precisión de las estimaciones. La magnitud del encogimiento depende de la varianza entre las unidades, y su efecto resulta particularmente benéfico cuando hay pocas observaciones dentro de una unidad, en cuyo caso hay una gran reducción de la incertidumbre ya que las estimaciones posteriores incorporan la información de otras unidades con menor variabilidad.
Incertidumbre en los parámetros. Asignar una distribución a los hiperparámetros, \(\theta\), nos permite incorporar nuestra incertidumbre sobre la distribución inicial de \(\lambda\).
Cómputo. La estructura jerárquica facilita los cálculos posteriores, debido a que la distribución posterior se factoriza en distribuciones condicionales más sencillas que facilitan la implementación de un muestreador de Gibbs.
Retomando el problema de estimación de tasas de mortalidad por transplante de corazón, modelaremos las \(\lambda_{j}\) con un modelo jerárquico, suponemos intercambiabilidad para reflejar que no contamos con información que nos permita distinguir entre los hospitales.
Primero definimos la distribución de los datos,
\[ \begin{eqnarray} \nonumber y_{j} \sim Poisson(e_{j}\lambda_{j}), \end{eqnarray} \]
donde \(y_{j}\) es el número de muertes observadas, \(e_{j}\) es el número de expuestos y \(\lambda_{j}\) es la tasa de mortalidad para el hospital \(j\), con \(j=1,...,94\).
Después asignamos una distribución al vector de parámetros \(\lambda=(\lambda_{1},...,\lambda_{94})\), para ello suponemos que las tasas de mortalidad \(\{\lambda_{1},...,\lambda_{94}\}\) son una muestra aleatoria de una distribución \(Gamma(\alpha,\alpha/\mu)\) con la forma
\[ \begin{eqnarray} \nonumber g(\lambda_j|\alpha,\mu)=\frac{(\alpha/\mu)^\alpha\lambda_j^{\alpha-1}exp(-\alpha\lambda_j/\mu)}{\Gamma(\alpha)}, \lambda_j>0. \end{eqnarray} \]
La media y varianza iniciales de \(\lambda_{j}\) están dadas por \(\mu\) y \(\mu^2/\alpha\), para toda \(j\). Las llamaremos la media y varianza poblacionales ya que son comunes para todos los hospitales. En la segunda etapa, los hiperparámetros \(\mu\) y \(\alpha\) se suponen independientes y les asignaremos iniciales vagas. Al parámetro de media,
\[ \begin{eqnarray} \nonumber h(\mu)\propto\frac{1}{\mu}, \mu>0. \end{eqnarray} \] Al parámetro de precisión \(\alpha\) le asignamos una densidad inicial propia pero plana, de la forma, \[ \begin{eqnarray} \nonumber h(\alpha)=\frac{z_{0}}{(\alpha+z_0)^2}, \alpha>0. \end{eqnarray} \]
El valor \(z_0\) es la mediana de \(\alpha\), no contamos con información inicial de forma que por ahora usaremos \(z_0=0.5\).
Debido a la estructura de independencia condicional del modelo jerárquico y a que se eligió una inicial conjugada, el análisis posterior es relativamente sencillo. Utilizamos el Teorema de Bayes para calcular la distribución posterior de \(\lambda_{j}\) condicional a los valores de los hiperparámetros \(\mu\) y \(\alpha\),
\[ \begin{eqnarray} \nonumber g(\lambda_{j}|y_{j},\alpha,\mu) &\propto& g(\lambda_{j}|\alpha,\mu)f(y_{j}|\lambda_{j})\\ \nonumber &=& \frac{(\alpha/\mu)^{\alpha} \lambda_{j}^{\alpha-1}exp(-\lambda_{j} \alpha/\mu)}{\Gamma(\alpha)}\frac{exp(-e_{j}\lambda_{j})(e_{j}\lambda_{j})^{y_{j}}}{y_{j}!}\\ \nonumber &\propto& \lambda_{j}^{y_{j}+\alpha-1}exp(-\lambda_{j}(e_{j}+\alpha/\mu)) \end{eqnarray} \]
obtenemos así que las tasas \(\{\lambda_{1},..., \lambda_{94}\}\) tienen distribuciones posteriores independientes \(Gamma(y_{j}+\alpha, e_{j}+\alpha/\mu)\), con media:
\[ \begin{eqnarray} E(\lambda_{j}|y,\alpha,\mu) &=& \frac{y_{j}+\alpha}{e_{j}+\alpha/\mu}\\ \label{eqn:pond} &=& (1-A_{j})\frac{y_{j}}{e_{j}}+A_{j}\mu, \end{eqnarray} \] donde \[ \begin{eqnarray} \label{eqn:factor} A_{j}=\frac{\alpha}{\alpha+e_{j}\mu}, \end{eqnarray} \]
Denominamos al factor \(A_{j}\) como el encogimiento hacia la media poblacional \(\mu\), más adelante derivamos la distribución posterior de \(\mu\), pero por ahora la enunciamos con el propósito de mostrar que su distribución incorpora información de todos los hospitales,
\[ \begin{eqnarray} \nonumber f(\mu|y)=K \int \prod_{i=1}^{94} \left[ \frac {(\alpha/\mu)^\alpha\Gamma(y_{i}+\alpha)} {(e_{i}+\alpha/\mu)^{y_{i}+\alpha}} \right ]\frac{z_{0}}{(\alpha+z_0)^2} \frac{1}{\mu} d\alpha \end{eqnarray} \] donde \(K\) es una constante.
Al escribir la media posterior de \(\lambda_{j}\) como un promedio ponderado, podemos ver el efecto de unir fuerzas mencionado en las observaciones del modelo jerárquico: hay un encogimiento hacia \(\mu\) que depende del número de expuestos, \(e_{j}\), para los hospitales con menor número de expuestos el encogimiento hacia \(\mu\) es mayor, mientras que para aquellos con mayor número de expuestos, es más importante la tasa observada, \(y_{j}/e_{j}\). De esta manera, mayor encogimiento corresponde a las observaciones con mayor incertidumbre.
Notemos también que la factorización de la media posterior es similar a la que obteníamos en el modelo de medias independientes. La diferencia radica en que ahora es un sólo modelo (opuesto a \(94\)), y los parámetros de la distribución inicial de \(\lambda_{j}\) forman parte del modelo de probabilidad pues les asignamos una distribución inicial.
Distribuciones posteriores
Sea \(\lambda=(\lambda_{1},...,\lambda_{94})\) y \(y=(y_{1},...,y_{94})\), calculamos la densidad posterior conjunta de los parámetros,
\[ \begin{align} \nonumber f(\lambda,\alpha,\mu|y) &\propto f(y|\lambda,\alpha,\mu)f(\lambda,\alpha,\mu)\\ \nonumber &= f(y|\lambda) f(\lambda|\alpha,\mu) p(\alpha,\mu)\\ \nonumber &= \prod_{i=1}^{94}f(y_{i}|\lambda_{i}) \prod_{i=1}^{94} f(\lambda_{i}|\alpha,\mu) f(\alpha)f(\mu)\\ \nonumber &\propto \prod_{i=1}^{94} \frac {exp(-e_{i}\lambda_{i})(e_{i}\lambda_{i})^{y_{i}}} {y_{i}!} \prod_{i=1}^{94} \frac {(\alpha/\mu)^{\alpha}\lambda_{i}^{\alpha-1}exp(-\lambda_{i}(\alpha/\mu))} {\Gamma(\alpha)} \frac{z_{0}}{(\alpha+z_0)^2} \frac{1}{\mu}\\ \nonumber &\propto \prod_{i=1}^{94}\frac {(e_{i}+\alpha/\mu)^{y_{i}+\alpha}\lambda_{i}^{y_{i}+\alpha-1}exp(-\lambda_{i}(e_{i}+\alpha/\mu))} {\Gamma(y_{i}+\alpha)} \prod_{i=1}^{94}\frac {(\alpha/\mu)^\alpha\Gamma(y_{i}+\alpha)} {(e_{i}+\alpha/\mu)^{y_{i}+\alpha}}\frac{z_{0}}{(\alpha+z_0)^2} \frac{1}{\mu}, \end{align} \]
de aquí podemos integrar las tasas de mortalidad, \(\lambda_{j}\), para obtener la distribución posterior de los hiperparámetros \(f(\alpha,\mu|y)\),
\[ {\normalsize \begin{align} \nonumber f(\alpha,\mu|y) \propto \int_{\lambda_{1}} ...\lambda_{y_{94}} \prod_{i=1}^{94}(\frac {(e_{i}+\alpha/\mu)^{y_{i}+\alpha}\lambda_{i}^{y_{i}+\alpha-1}exp(-\lambda_{i}(e_{i}+\alpha/\mu))} {\Gamma(y_{i}+\alpha)}) \prod_{i=1}^{94}k_i d\lambda_{1}...d\lambda_{94},\\ \nonumber \end{align} } \]
donde,
\[ \normalsize{ \begin{align} \nonumber k_i = \frac {(\alpha/\mu)^\alpha\Gamma(y_{i}+\alpha)} {(e_{i}+\alpha/\mu)^{y_{i}+\alpha}}\frac{z_{0}}{(\alpha+z_0)^2} \frac{1}{\mu} \end{align}} \]
observemos que las \(\{k_j\}\) no dependen de \(y\) por lo que son constantes en la integral, además para cada \(i\) de la primera multiplicación tenemos una distribución \(Gamma(y_{i}+\alpha, e_{i}+\alpha/\mu)\) por lo que integran \(1\).
Resultando,
\[ {\normalsize \begin{align} \nonumber f(\alpha,\mu|y)=K\prod_{i=1}^{94} \frac {(\alpha/\mu)^\alpha\Gamma(y_{i}+\alpha)} {(e_{i}+\alpha/\mu)^{y_{i}+\alpha}}\frac{z_{0}}{(\alpha+z_0)^2} \frac{1}{\mu} \end{align}} \]
donde \(K\) es la constante de proporcionalidad.
Simulemos de las distribuciones posteriores, para ello procederemos como sigue:
Simulamos \((\mu, \alpha)\) de la distribución marginal posterior.
Simulamos \(\lambda_1,...,\lambda_{94}\) de la distribución posterior condicional a los valores simulados \((\mu, \alpha)\).
Para el primer paso, notamos que ambos parámetros son positivos por lo que es conveniente transformarlos: \(\theta_1 = log(\alpha\), \(\theta_2 = log(\mu)\).
Definimos ahora la distribución posterior en términos de los parámetros transformados
# código Albert paquete LearnBayes
poissgamexch <- function(theta, datapar){ # theta = c(theta_1, theta_2)
y <- datapar$data[, 2]
e <- datapar$data[, 1]
z0 <- datapar$z0
alpha <- exp(theta[1])
mu <- exp(theta[2])
beta <- alpha/mu
logf <- function(y, e, alpha, beta){
lgamma(alpha + y) - (y + alpha) * log(e + beta) + alpha*log(beta) -
lgamma(alpha)
}
val <- sum(logf(y, e, alpha, beta))
val <- val + log(alpha) - 2 * log(alpha + z0)
return(val)
}
# Simulamos theta_1, theta_2 usando el algoritmo de Metropolis dentro de Gibbs
# en la función gibbs, datapar contiene la base de datos y el valor del
# hiperparámetro z0
datapar <- list(data = hearttransplants, z0 = 0.53)
# adicionalmente debemos dar valores para el algoritmo Metrópolis, la función
# implementa un algoritmo de caminata aleatoria
# donde la distribución propuesta tiene la forma theta* = theta^t-1 + scale*Z
# y Z es N(0, I), en este caso c(1, 0.15) es el vector de escala
fitgibbs <- gibbs(poissgamexch, start = c(4, -7), m = 1000, scale = c(1, 0.15),
datapar)
fitgibbs$accept
#> [,1] [,2]
#> [1,] 0.529 0.485
# simulaciones de alpha
alpha <- exp(fitgibbs$par[, 1])
# simulaciones de mu
mu <- exp(fitgibbs$par[, 2])Podemos usar las simulaciones de \(\alpha\) y \(\mu\) para ver el encogimiento de las estimaciones de cada hosiptal hacia la media poblacional. Notamos un mayor encogimiento para los hospitales con menor número de expuestos.
heart_jer <- heart %>%
rowwise() %>%
mutate(A = mean(alpha / (alpha + e * mu)))
ggplot(heart_jer, aes(x = log(e), y = A)) +
geom_point(alpha = 0.6, size = 1.6) +
scale_x_continuous("Número de expuestos (e)", label = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
ylab("encogimiento (A)") + ylim(0, 1)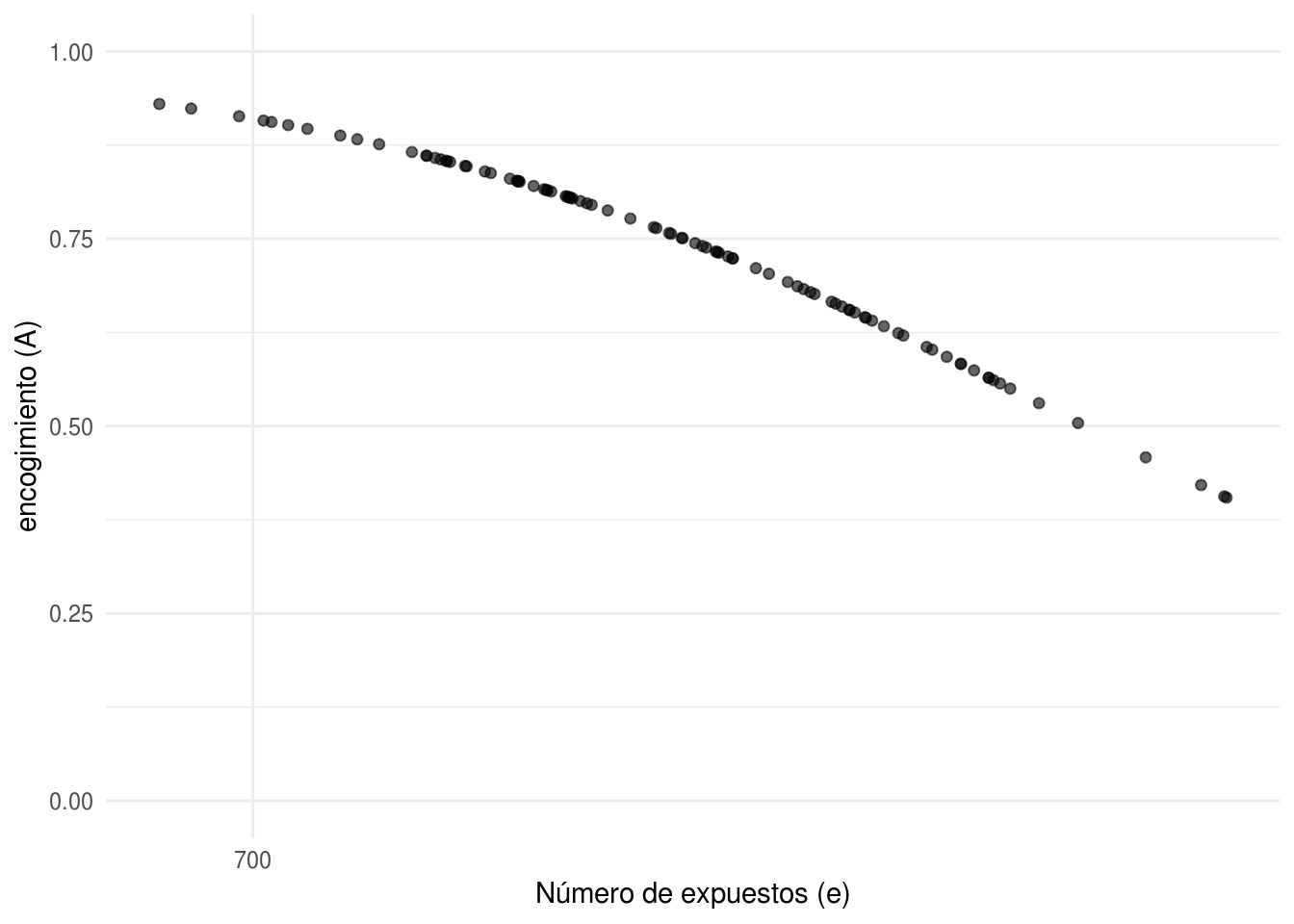
Ahora simualmos observaciones de la distribución posterior de \(\lambda\):
heart_jer_sims <- heart_jer %>%
mutate(sims = map2(e, y, ~rgamma(1000, .y + alpha, .x + alpha / mu))) %>%
ungroup()Ya que tenemos las distribuciones posteriores podemos hacer inferencia acerca de la tasa de mortalidad \(\lambda\). A continuación graficamos los intervalos posteriores del \(95\%\) de probabilidad para las tasas \(\lambda_{j}\), el color representa el número de muertes observadas \(y_{j}\), en gris se graficaron las tasas observadas, la gráfica se dividió en \(3\) páneles de acuerdo al número de muertes observadas en los hospitales.
# Creamos intervalos con las simulaciones
heart_jer_post <- heart_jer_sims %>%
mutate(
media = map_dbl(sims, ~mean(1000 * .)),
int_l = map_dbl(sims, ~quantile(1000 * ., 0.025)),
int_u = map_dbl(sims, ~quantile(1000 * ., 0.975)),
sims_y = map2(sims, e, ~rpois(1000, .x * .y))
)
ggplot(heart_jer_post, aes(x = log(e), y = media, color = factor(y))) +
geom_pointrange(aes(ymin = int_l, ymax = int_u), size = 0.3) +
geom_point(data = heart, aes(x = log(e), y = 1000 * y / e), color = "black",
alpha = 0.6) +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
scale_colour_hue("muertes obs. (y)") +
ylab("Muertes por 1000 expuestos")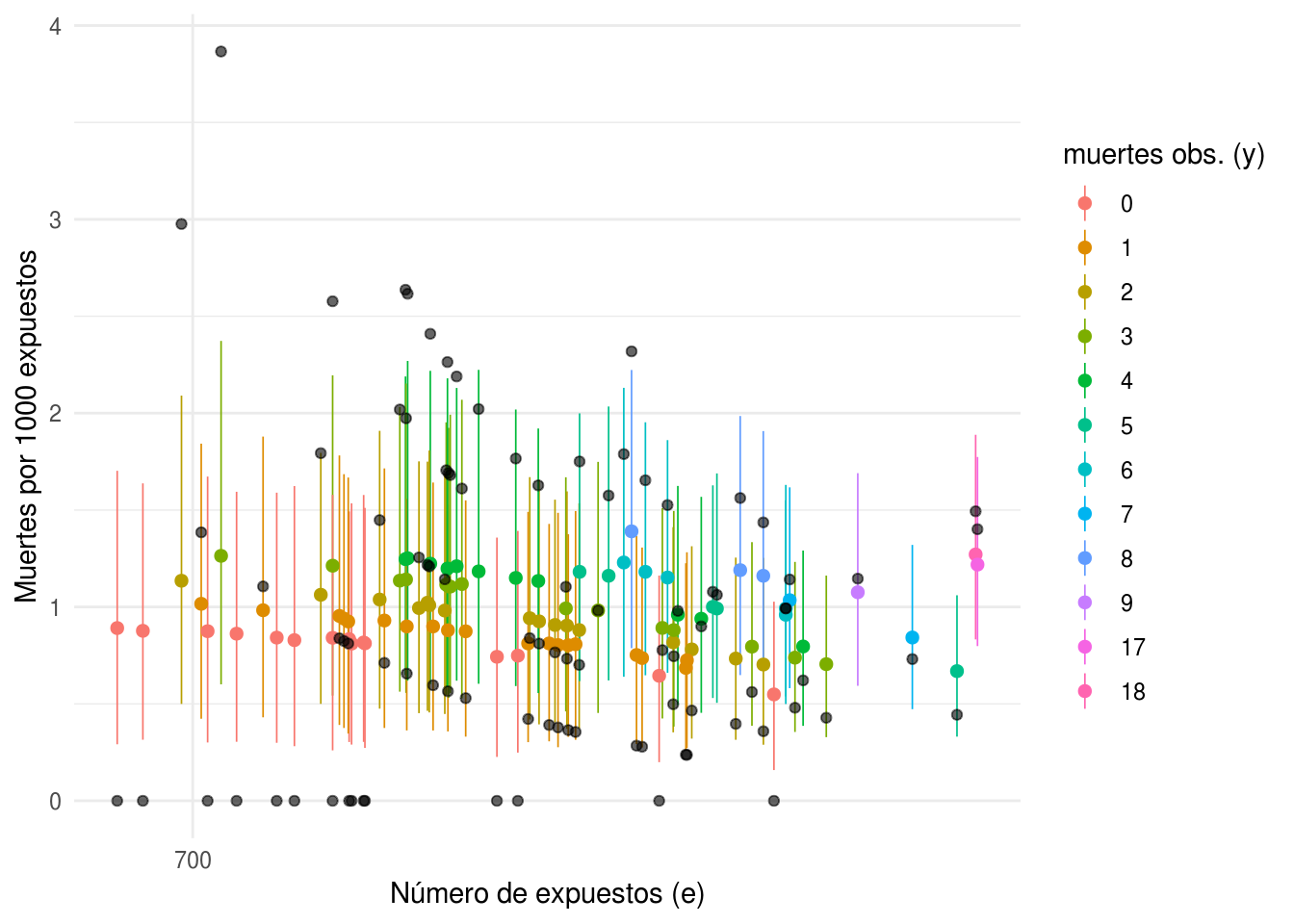
Analizamos la distribución predictiva posterior para la misma muestra de \(10\) hospitales que se utilizó en el modelo de unidades iguales.
sims_muestra <- heart_jer_post %>%
filter(hospital %in% heart_sims_sample$hospital)
sims_unnest <- sims_muestra %>%
dplyr::select(hospital, e, y, sims_y) %>%
unnest()
ggplot(sims_unnest, aes(x = sims_y)) +
geom_histogram(aes(y = ..density..), binwidth = 1, color = "darkgray",
fill = "darkgray") +
facet_wrap(~ hospital, nrow = 2) +
geom_segment(data = sims_muestra, aes(x = y, xend = y, y = 0, yend = 0.5),
color = "red") +
geom_text(data = sims_muestra, aes(x = 10, y = 0.4, label = paste("e =", e)),
size = 2.7, color = "red")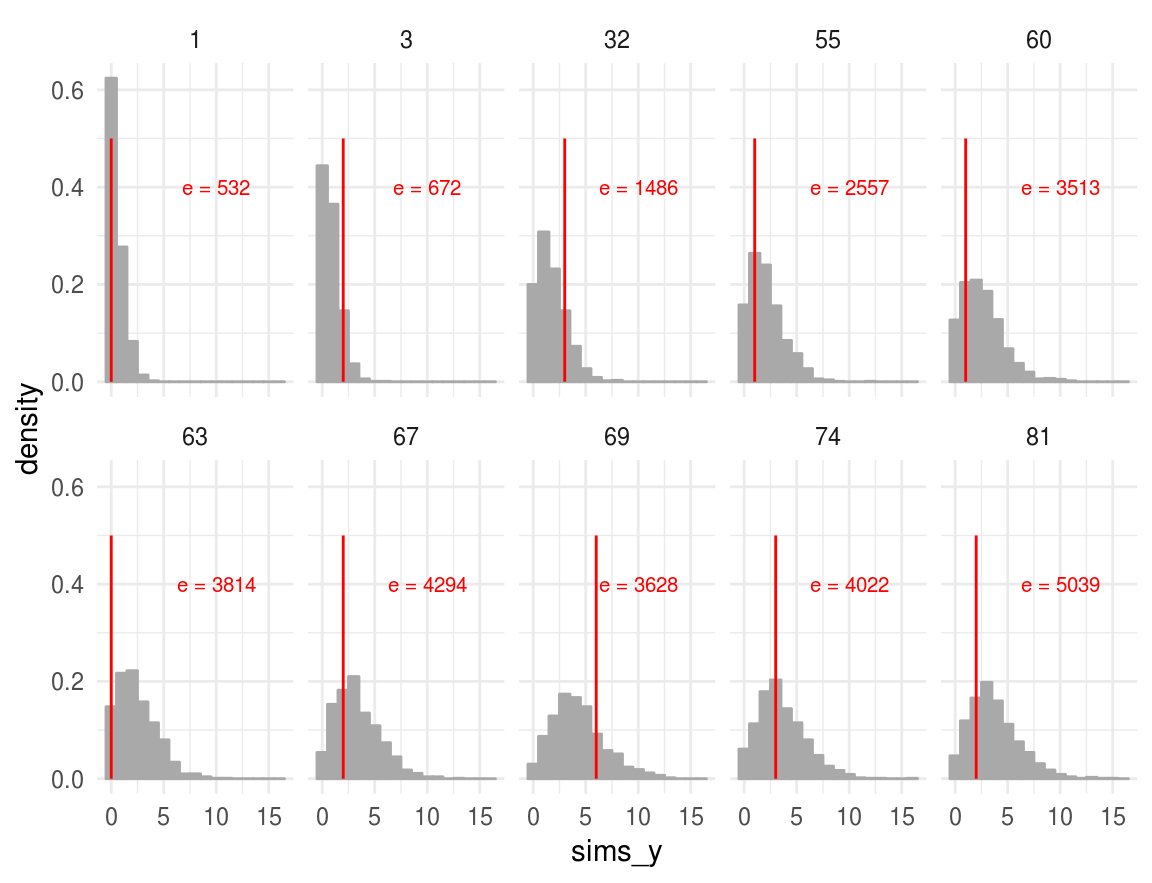
Observemos que únicamente en uno de los histogramas el número de muertes observadas se encuentra cerca de la cola de la distribución, lo que indica concordancia de las observaciones con el modelo ajustado.
Finalmente, revisamos la consistencia de los valores observados \(y_{j}\) con la distribución predictiva posterior para todos los hospitales, para ello calculamos la probabilidad de que una observación futura \(y_{j}^*\) sea al menos tan extrema como \(y_{j}\) para todas las observaciones:
\[ \begin{eqnarray} \nonumber P(extremos) = min\{P(y_{j}^*\leq y_{j}),P(y_{j}^*\geq y_{j})\} \end{eqnarray} \]
A continuación graficamos las probabilidades de extremos (calculadas con simulación). Con el modelo jerárquico solamente el \(6\%\) de las probabilidades son menores al \(0.15\), una disminución considerable al \(28\%\) obtenido con el modelo de unidades iguales.
# Para calcular las p predictiva podemos usar las simulaciones
p_pred <- heart_sims %>%
unnest() %>%
group_by(hospital) %>%
summarise(
p = min(sum(sims <= y) / 1000, sum(sims >= y) / 1000),
e = first(e)
)
p_pred_indep_jer <- heart_jer_post %>%
unnest() %>%
group_by(hospital) %>%
summarise(p_jer = min(sum(sims_y <= y) / 1000, sum(sims_y >= y) / 1000)) %>%
left_join(p_pred)
#> Joining, by = "hospital"
ggplot(p_pred_indep_jer, aes(x = log(e), y = p_jer)) +
geom_point() +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
ylab("P(extremos)") +
geom_hline(yintercept = .15, colour = "red", size = 0.4) +
ylim(0, .7) 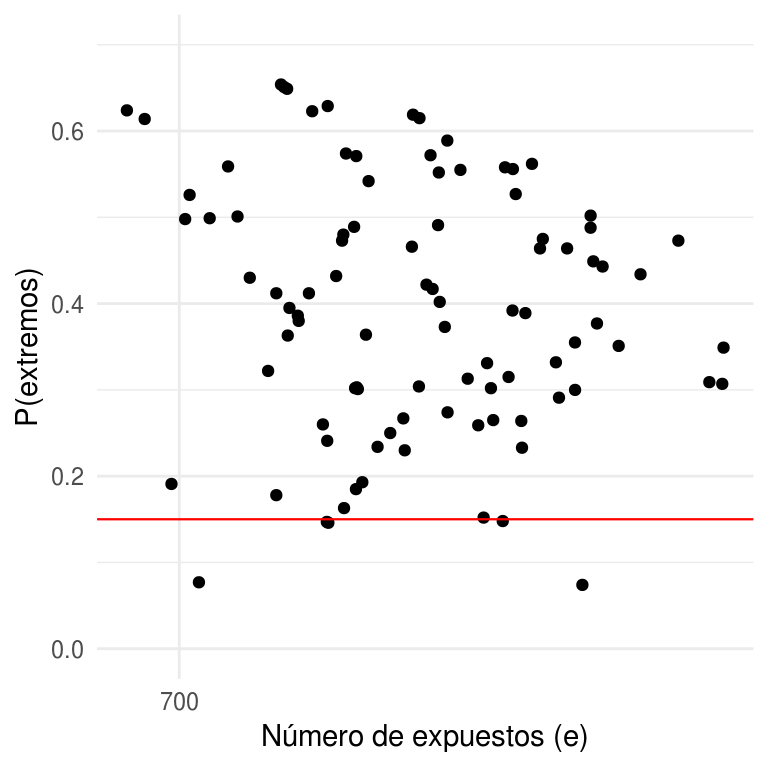
Comparemos ahora las probabilidades de al menos tan extremo usando el modelo jerárquico contra las probabilidades de al menos tan extremo usando el modelo de unidades iguales, los puntos se colorearon de acuerdo al número de expuestos de cada hospital. Observemos que las probabilidades bajo el modelo jerárquico son mayores en la mayoría de los casos.
p_pred_indep_jer <- p_pred_indep_jer %>%
mutate(e_cat = Hmisc::cut2(e, c(500, 1500, 2500, 4000, 12500)))
ggplot(p_pred_indep_jer, aes(x = p, y = p_jer, colour = e_cat)) +
geom_abline(colour = "red", size = 0.4, alpha = 0.8) +
geom_point(size = 2.5) +
coord_equal() +
xlab("P(extremos), unidades iguales") +
ylab("P(extremos), jerárquico") +
ylim(0, 0.7) +
xlim(0, 0.7) +
coord_equal() +
scale_colour_manual("No. expuestos (e)", values = c("#a6cee3", "#1f78b4",
"#b2df8a", "#33a02c")) + theme_minimal()
#> Coordinate system already present. Adding new coordinate system, which will replace the existing one.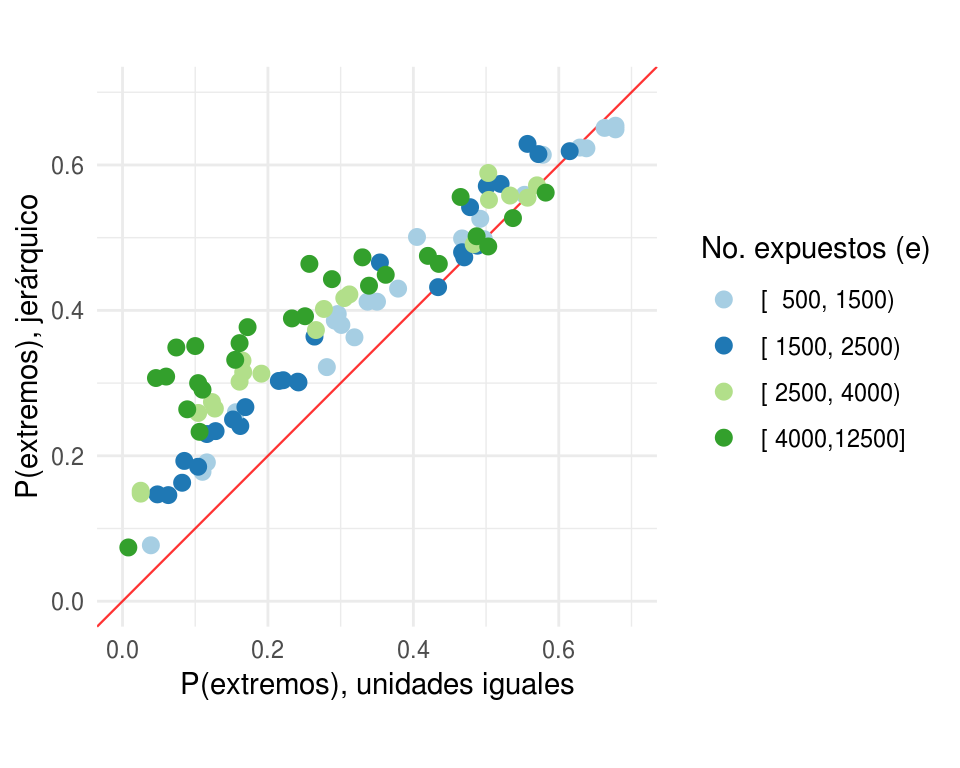
JAGS
Ahora veremos como hacer la estimación usando JAGS. Primero hacemos un par de cambios en la definición del modelo, esto es porque la distribución inicial de \(\mu\) no es propia (i.e. no integra uno) y JAGS no permite el uso de iniciales impropias. Usaremos iniciales \(Gamma\) para \(\alpha\) y \(\mu\) eligiendo parámetros de manera que sean iniciales vagas. \[\mu, \alpha \sim Gamma(0.01, 0.01).\] Veamos como se escriben el modelo en JAGS.
modelo_heart.txt <-
'
model{
for(i in 1 : N) {
y[i] ~ dpois(lambda2[i])
lambda2[i] <- e[i] * lambda[i]
lambda[i] ~ dgamma(alpha, beta)
}
alpha ~ dgamma(0.01, 0.01)
mu ~ dgamma(0.01, 0.01)
beta <- alpha/mu
}
'
cat(modelo_heart.txt, file = 'modelo_heart.txt')En el modelo definimos una distribución de probabilidad para cada hospital, es por ello que usamos el ciclo for, dentro del ciclo modelamos también las tasas de mortalidad como observaciones de una distribución \(Gamma(\alpha, \alpha/\mu)\), y finalmente fuera del ciclo especificamos la distribución de los hiperparámetros.
library(R2jags)
head(heart)
#> e y hospital
#> 1 532 0 1
#> 2 584 0 2
#> 3 672 2 3
#> 4 722 1 4
#> 5 904 1 5
#> 6 1236 0 6
# creamos una lista con los datos: esta incluye índices, y variables
N <- nrow(heart)
e <- heart$e
y <- heart$y
jags.data <- list("e", "y", "N")
# ahora definimos valores iniciales para los parámetros, en este caso estamos
# generando valores iniciales aleatorios de manera de que distintas cadenas
# tengan distitos valoes iniciales
# si no se especifican la función jags generará valores iniciales
jags.inits <- function(){
list("alpha" = runif(1),
"mu" = runif(1),
"lambda" = runif(N))
}
# debemos especificar también el nombre de los parámetros que vamos a guardar
jags.parameters <- c("alpha","mu","lambda", "y")
# Y usamos la función jags (más adelante discutiremos los otros parámetros de
# la función)
jags.fit <- jags(data = jags.data, inits = jags.inits,
model.file = "modelo_heart.txt", parameters.to.save = jags.parameters,
n.chains = 2, n.iter = 5000)
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 94
#> Unobserved stochastic nodes: 96
#> Total graph size: 381
#>
#> Initializing model
plot(jags.fit)
class(jags.fit)
#> [1] "rjags"
names(jags.fit)
#> [1] "model" "BUGSoutput" "parameters.to.save"
#> [4] "model.file" "n.iter" "DIC"
names(jags.fit$BUGSoutput)
#> [1] "n.chains" "n.iter" "n.burnin"
#> [4] "n.thin" "n.keep" "n.sims"
#> [7] "sims.array" "sims.list" "sims.matrix"
#> [10] "summary" "mean" "sd"
#> [13] "median" "root.short" "long.short"
#> [16] "dimension.short" "indexes.short" "last.values"
#> [19] "program" "model.file" "isDIC"
#> [22] "DICbyR" "pD" "DIC"
# las simulaciones de la distribución posterior se pueden extraer del objeto
# fit$BUGSoutput como arreglo: sims.array, lista: sims.list o matriz: sims.matrix
# aquí elegimos el formato de lista
names(jags.fit$BUGSoutput$sims.list)
#> [1] "alpha" "deviance" "lambda" "mu" "y"
# y extraemos las lambdas
class(jags.fit$BUGSoutput$sims.list$lambda)
#> [1] "matrix"
# vienen en formato de matriz donde los renglones son las iteraciones y cada
# columna corresponde a un hospital
lambda_sims <- jags.fit$BUGSoutput$sims.list$lambda
# los guardamos en un data.frame
p_pred_jags <- data.frame(n_sim = 1:nrow(lambda_sims), lambdas = lambda_sims) %>%
gather(hospital, sims, -n_sim) %>%
mutate(
hospital = str_replace(hospital, fixed("."), ""),
hospital = parse_number(hospital)
) %>%
group_by(hospital) %>%
summarise(
media = mean(sims),
int_l = quantile(sims, 0.025),
int_u = quantile(sims, 0.975)
) %>%
left_join(heart)
ggplot(p_pred_jags, aes(x = log(e), y = media, color = factor(y))) +
geom_pointrange(aes(ymin = int_l, ymax = int_u), size = 0.3) +
geom_point(aes(x = log(e), y = y/e), color = "black", alpha = 0.6) +
scale_x_continuous("Número de expuestos (e)", labels = exp,
breaks = map_dbl(0:4, ~ log(700 ^ .))) +
scale_colour_hue("muertes obs. (y)") +
ylab("Muertes por 1000 expuestos")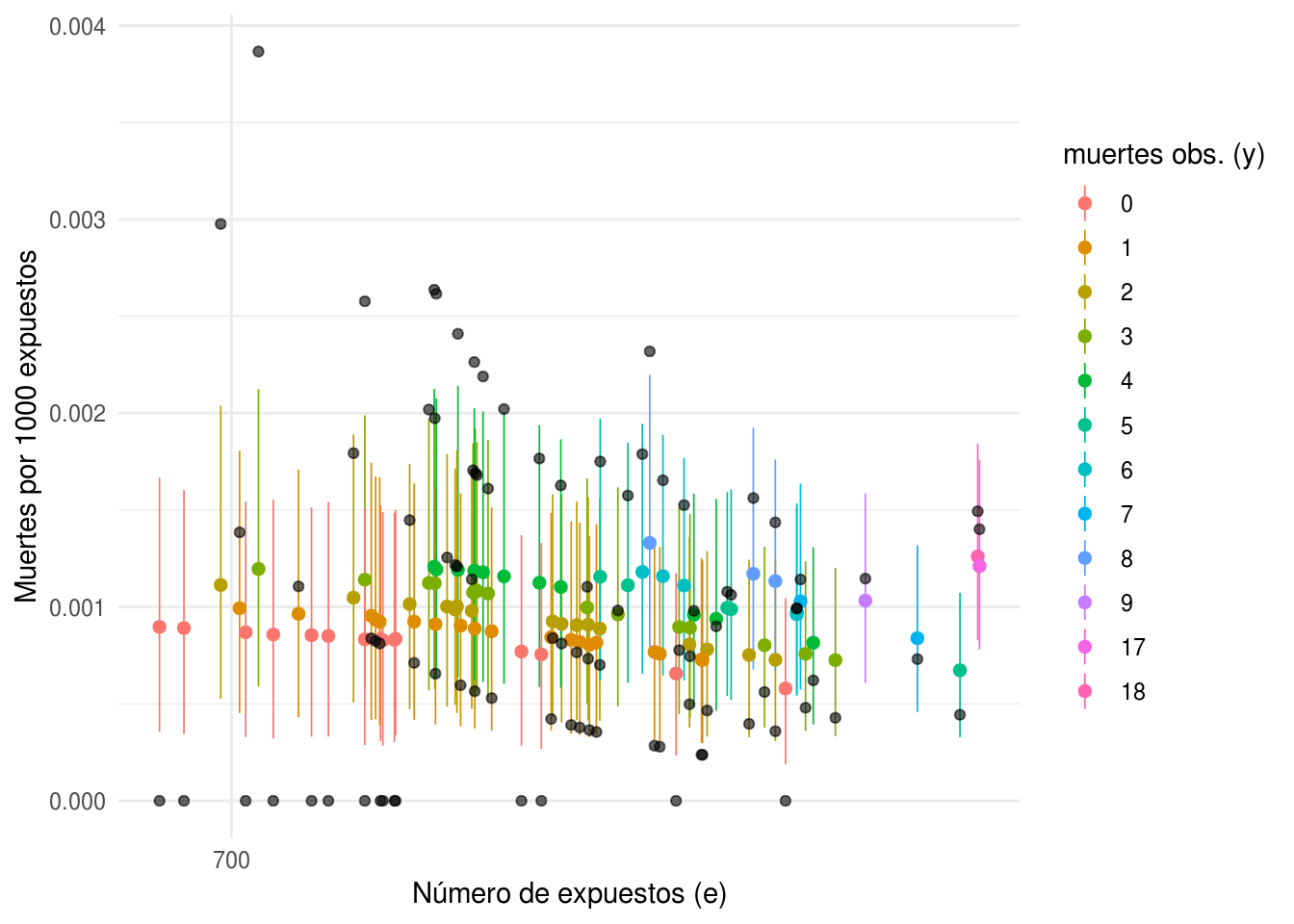
 Implementaremos varios modelos en JAGS o Stan, la
base de datos que usaremos contiene información de mediciones de radón
(activity) y del suelo en el que se hicieron las mediciones (floor = \(0\) casas
con sótano, floor = \(1\) casas sin sótano), las mediciones corresponden a \(919\)
hogares muestreados de \(85\) condados de Minnesota, (este es ejercicio se tomó
de Gelman and Hill (2007)). El objetivo es construir un
modelo de regresión en el que la medición de radón es la variable independiente
y el tipo de suelo es la covariable.
Implementaremos varios modelos en JAGS o Stan, la
base de datos que usaremos contiene información de mediciones de radón
(activity) y del suelo en el que se hicieron las mediciones (floor = \(0\) casas
con sótano, floor = \(1\) casas sin sótano), las mediciones corresponden a \(919\)
hogares muestreados de \(85\) condados de Minnesota, (este es ejercicio se tomó
de Gelman and Hill (2007)). El objetivo es construir un
modelo de regresión en el que la medición de radón es la variable independiente
y el tipo de suelo es la covariable.
- Iniciaremos con un modelo de regresión de unidades iguales, este modelo ignora la variación en los niveles de radón entre los condados.
\[y_i \sim N(\alpha + \beta x_i, \sigma_y^2) \]
- Después pasamos a un modelo de unidades independientes, en este simplemente incluímos indicadoras a nivel condado.
\[y_i \sim N(\alpha_{j[i]} + \beta x_i, \sigma_y^2) \]
Añadimos una estructura jerárquica al modelo: \[y_i \sim N(\alpha_{j[i]} + \beta x_i, \sigma_y^2) \] \[\alpha_j \sim N(\mu_{\alpha}, \sigma_{\alpha}^2)\]
Incorporamos una covariable \(u_j\) a nivel grupo, en este caso elegiremos una medición de uranio a nivel condado (Uppm).
\[y_i \sim N(\alpha_{j[i]} + \beta x_i, \sigma_y^2) \] \[\alpha_j \sim N(\gamma_0 + \gamma_{1}u_j, \sigma_{\alpha}^2)\]
Utiliza el modelo anterior para predecir el valor de radón para una nueva casa sin sótano (floor = \(1\)) en el condado \(26\).
Utiliza el modelo anterior para predecir el valor de radón para una nueva casa sin sótano (floor = \(1\)) en un condado nuevo con nivel de uranio \(2\).
** Observaciones**
Iniciamos preparando los datos para el análisis, trabajaremos en escala logarítmica, hay algunos casos con medición cero, para éstos hacemos una pequeña correción redondeándolos a \(0.1\).
Ahora, por el momento hemos modelado los datos y los parámetros \(\alpha_j\) a nivel grupo (en el caso del modelo jerárquico), pero nos falta asignar distribuciones a los hiperparámetros (\(\mu, \beta, \sigma_y^2, \sigma_{\alpha}^2\)). Para la elección de distribuciones iniciales (de los hiperparámetros) podemos usar iniciales no informativas. Recordemos que una distribución inicial no informativa tiene el objetivo de permitir que realicemos inferencia bayesiana para parámetros de los cuales no sabemos mucho (sin considerar la información en los datos). Consideremos las siguientes distribuciones iniciales: \[\beta \sim N(0, 0.0001)\] \[\mu_{\alpha} \sim N(0, 0.0001)\] donde la normal esta parametrizada en términos de varianzas inversas (conocidas como precisión \(\tau = 1/\sigma^2\)). Con los parámetros propuestos estaríamos diciendo que esperamos que los coeficientes se ubiquen en el rango \((-100,100)\) y si los estimadores estan en este rango la distribución inicial provee muy poca información. Para los parámetros restantes podemos definirla la inicial de la siguiente manera: \[\tau_y = 1/\sigma^2\] donde \[\sigma^2 \sim Unif(0, 100)\] y \[\tau_{\alpha} = 1/\sigma_{\alpha}^2\] donde \[\sigma_{\alpha}^2 \sim Unif(0, 100).\]
Entonces, para que una distribución inicial sea noinformariva, su rango de incertidumbre debe ser más amplio que el rango de valores razonables que pueden tomar los parámetros.
Ejemplo: conteo rápido
Objetivo: Estimar resultados de la elección a partir de una muestra aleatoria de casillas.
Inferencia basada en modelos: Modelo de regresión multinivel, en función de covariables asociadas a las casillas, que estima el número de votos a favor del candidato en cada casilla.
Calibración: Evaluamos modelos con remuestreo y datos de elecciones pasadas, revisando cobertura de intervalos de confianza/credibilidad.
Experiencia: Mostramos resultados de elección 2018.
Contexto: Conteo rápido
En México, las elecciones tienen lugar un domingo, los resultados oficiales del proceso se presentan a la población una semana después. A fin de evitar proclamaciones de victoria injustificadas durante ese período el INE organiza un conteo rápido.
Conteo rápido: Procedimiento para estimar el porcentaje de votos a favor de los candidatos en el día de la elección, consiste en seleccionar una muestra aleatoria de las casillas de votación y analizar sus resultados para presentar intervalos con una probabilidad de al menos 0.95.
La rapidez y precisión del conteo favorece un ambiente de confianza y sirve como una herramienta contra el fraude.
Elecciones 2018
La elección del 2018 fue la más grande que se ha vivido en México, con 3,400 puestos en disputa. Se realizaron conteos rápidos para 9 elecciones estatales simultáneas a un conteo rápido para la elección de presidente.
El día de la elección, el sistema de información comienza a las 6 p.m. y, cada 5 minutos, produce una secuencia de archivos acumulativos. Estas muestras parciales se analizan con los métodos de estimación para rastrear la tendencia de los resultados.
Las muestras parciales tienen un sesgo potencial asociado al patrón de llegada de la información.
Diseño de la muestra
El diseño de la muestra es probabilístico.
- Diseño: es unietápico y estratificado, donde la unidad de observación es
la casilla.
- En Guanajuato son 22 estratos definidos por distrito local.
- Tamaño de muestra: Se eligió el tamaño de muestra para lograr intervalos
de 95% confianza con longitud máxima de 2 puntos porcentuales.
- En Guanajuato el tamaño de muestra se fijó en 500 casillas.
Selección de la muestra: La distribución de la muestra en las casillas se realizó proporcional al número de casillas en cada estrato, y se utilizó muestreo aleatorio simple dentro de cada estrato.
Consideraciones adicionales: Se buscó que todos los estratos tuvieran al menos 50 casillas, y que porcentaje de CAEs (Capacitadores-Asistentes Electorales) encargados de más de una casilla fuera menor a 20%.
Datos faltantes
En la práctica la muestra seleccionada no llega completa. Entre las posibles razones de faltantes están:
El clima en ciertas regiones dificulta la transmisión de los resultados.
El responsable de reportar los resultados está saturado de trabajo: contando votos a falta de funcionarios de casilla, retrasado por la dificultad de llegar a la casilla por malas condiciones de terreno,…
Usualmente los faltantes no son completamente aleatorios, esto es, la probabilidad de que una casilla no se reporte está asociada a la respuesta de la casilla.
Buscamos un modelo con tratamiento consistente de datos faltantes: en ausencia de respuesta.
Antecedentes
El modelo que proponemos se desarrolló con base a tres referencias:
- Mendoza and Nieto-Barajas (2016) Quick counts in the Mexican presidential elections: A Bayesian
approach. En este trabajo se propone el uso de modelos bayesianos para el
conteo rápido.
- Se ajusta un modelo de manera independiente para cada candidato en cada estrato.
- Modelo normal para el total de votos \(X_k\) que recibe cada candidato en la \(k\)-ésima casilla. \[X_k\sim N \bigg( n_{k} \theta, \tau / n_k \bigg)\]
- \(\theta\): proporción de gente de la lista nominal a favor del candidato.
- \(n_k\): número de personas en la lista nominal de la \(k\)-ésima casilla.
Lehtonen (2012) Calibrated Bayes, an Alternative Inferential Paradigm for Official Statistics. Se describe un acercamiento bayesiano para los problemas clásicos de muestreo, usando modelos jerárquicos, el paradigma que se propone en este artículo consiste en ajustar modelos bayesianos y evaluarlos (calibrarlos) usando propiedades frecuentistas.
Park, Gelman, and Bafumi (2004) Bayesian Multilevel Estimation with Poststratification: State-Level Estimates from National Polls. Se describe un modelo jerárquico para estimar preferencias electorales a partir de encuestas de opinión pública, además de la estructura jerárquica se incluyen covaribales.
Es así que tomamos como base el modelo propuesto en Mendoza and Nieto-Barajas (2016) y siguiendo los otros dos artículos comenzamos extendiendolo en 2 sentidos:
Usamos un enfoque unificado por candidato, en lugar de estimar un modelo independiente dentro de cada estrato, ajustamos un un único modelo por candidato incluyendo un efecto aleatorio (estructura multinivel) que corresponda al estrato.
Agregamos covariables que describen la casilla para mejorar la eficiencia en la estimación y corregir sesgos ante faltantes.
Inferencia en muestreo
Antes de pasar al modelo describimos como encaja la metodología que proponemos en el mundo del muestreo. Cuando se hace inferencia de muestreo hay dos grandes acercamientos:
Inferencia basada en diseño de muestras. Los valores poblacionales son una cantidad fija, la inferencia se basa en la distribución de probabilidad asociada a la selección de la muestra.
- Inferencia basada en modelos. Las variables provienen de un modelo
estadístico:
Modelos de superpoblaciones: los valores poblacionales se consideran una muestra aleatoria de una superpoblación, y se les asigna una distribución de probabilidad.
Modelos bayesianos: agregamos distribuciones iniciales a los parámetros y se hace inferencia de las cantidades poblacionales y de los parámetros usando la distribución posterior.
Modelos bayesianos
En modelos bayesianos la inferencia se realiza prediciendo la variable de interés para las unidades de la población que no se incluyeron en la muestra y para las unidades que no respondieron, condicional a la muestra observada y al modelo.
Usamos modelos paramétricos:
\[p(y|x)=\int p(y|x, \theta)p(\theta|x)p(\theta)d\theta\]
\(p(y|x,\theta)\): modelo paramétrico de \(y\).
\(p(\theta|x)\): distribución inicial para \(\theta\).
Se incluyen en el modelo las variables involucradas en el diseño de la muestra (estratos, conglomerados).
Modelo con distribución normal
En el caso del modelo del conteo rápido incluímos las siguientes covariables:
Tipo de sección (rural o urbana/mixta).
Tipo de casilla (básica/contigua/especial o extraordinaria).
Tamaño de sección (chica < 1000 votantes, mediana [1000, 5000], grande > 5000).
Región (oriente u occidente).
Distrito local.
Interacción de tipo de sección con tamaño de sección.
Y el primer modelo que planteamos es como sigue:
Sea \(X_k\) el número de votos en favor del candidato en la k-ésima casilla:
- Nivel 1 \[ \begin{align} X_k \sim \mathsf{N}(n_k\theta_k, \tau_k^{\text{distrito}}/n_k) \ \mathcal{I}_{[0,750]}, \end{align} \]
donde \(n_k\) es la lista nominal y \(\theta_k\) la proporción de personas en la lista nominal de la casilla \(k\) que votaron por el candidato,
\[\begin{align} \theta_k=\text{logit}^{-1}&(\beta^0+\beta^{\text{rural}}\cdot\text{rural}_k+\beta^{\text{rural-tamañoM}}\cdot\text{rural}_k\cdot\text{tamañoM}_k\\+&\beta^{\text{tamañoM}}\cdot\text{tamañoM}_k +\beta^{\text{tamañoL}} \cdot \text{tamañoL}_k+\beta^{\text{tipoSP}}\cdot \text{tipoSP}_k\\+&\beta^{\text{distrito}}_{\text{distrito}(k)}), \end{align}\]
- Nivel 2
\[\begin{align} \beta^{\text{distrito}}_{j}\sim \mathsf{N}\left(\mu^{\text{distrito}}, \sigma_{\text{distrito}}^2\right). \end{align}\]
El código del modelo en JAGS:
library(quickcountmx)
eval(parse(text = deparse(quickcountmx:::model_norm)[3]))#> Warning in gzfile(file, "rb"): cannot open compressed file 'cache_manual/
#> model_string_norm.rds', probable reason 'No such file or directory'
#> Error in gzfile(file, "rb"): cannot open the connectionmodel_string %>% cat
#> Error in eval(lhs, parent, parent): object 'model_string' not foundSe utilizó una parametrización redundante para acelerar la convergencia:
beta_estrato[j] <- beta_estrato_raw[j] - mean(beta_estrato_raw[])
beta_estrato_raw[j] ~ dnorm(mu_estrato, tau_estrato)ver el capítulo 19 de Gelman and Hill (2007).
La función mrp_party_estimation() recibe la tabla de datos, el partido que
se desea ajustar, la variable de estratificación, la fracción de la muestra a
utilizar en el ajuste, el número de iteraciones, calentamiento, número de
cadenas, semilla y el modelo que vamos a ajustar.
gto_pan_norm <- mrp_party_estimation(gto_2012, pan_na,
stratum = distrito_loc_17, frac = 0.06, n_iter = 2000, n_burnin = 1000,
n_chains = 2, seed = 19291, model_string = "model_norm")#> Warning in gzfile(file, "rb"): cannot open compressed file 'cache_manual/
#> gto_pan_norm.rds', probable reason 'No such file or directory'
#> Error in gzfile(file, "rb"): cannot open the connection
#> Error in eval(expr, envir, enclos): object 'gto_pan_norm' not foundEn fit se guarda la salida de JAGS y n_votes es el vector de simulaciones
del total de votos.
plot(gto_pan_norm$fit)
#> Error in plot(gto_pan_norm$fit): object 'gto_pan_norm' not foundDe la imagen anterior podemos ver que faltan iteraciones para alcanzar
convergencia. Las parámetros beta_estrato_raw se crearon para acelerar la
convergencia pero no es necesario que converjan, pero otras variables como
beta_region se beneficiarían de incrementar las simulaciones.
El siguiente código corre el modelo para todos los partidos, incrementando las simulaciones.
gto_norm <- mrp_estimation(gto_2012, ... = pri_pvem:otros,
stratum = distrito_loc_17, frac = 0.06, n_iter = 3000, n_burnin = 2000,
n_chains = 2, seed = 19291, parallel = TRUE, n_cores = 4,
model_string = "model_norm")La salida incluye los objetos que regresa ña función jags() para cada partido
y una tabla con un resumen de los resultados.
#> Warning in gzfile(file, "rb"): cannot open compressed file 'cache_manual/
#> gto_norm.rds', probable reason 'No such file or directory'
#> Error in gzfile(file, "rb"): cannot open the connection
#> Warning in file(file, "rt"): cannot open file 'data/gto_2012.csv': No such
#> file or directory
#> Error in file(file, "rt"): cannot open the connectionnames(gto_norm)
#> Error in eval(expr, envir, enclos): object 'gto_norm' not found
gto_norm$post_summary
#> Error in eval(expr, envir, enclos): object 'gto_norm' not foundInferencia del modelo
- La inferencia de \(\theta\) se obtiene de la distribución posterior: \[p(\theta|y_{obs},x)\propto p(\theta|x)L(\theta|y_{obs},x)\]
- La posterior de \(\theta\) lleva a inferencia de las cantidades poblacionales no observadas usando la distribución predictiva posterior: \[p(y_{falta}|y_{obs},x) = \int p(y_{falta}|\theta,x)p(\theta|y_{obs},x)d\theta\]
- Utilizamos los datos observados y simulaciones de los datos faltantes para estimar la proporción de votos en favor de cada candidato.
Evaluación de ajuste
La siguientes gráficas muestra la distribución predictiva posterior del total de votos para el PAN (partido ganador) y para Movimiento Ciudadano (partido chico), la línea roja indica el total de votos observado.
norm_votes <- map_df(gto_norm$jags_fits, ~apply(.$BUGSoutput$sims.list$x, 1, sum)) %>%
mutate(n_sim = 1:n()) %>%
gather(party, votes, -n_sim) %>%
mutate(party = reorder(party, votes))
#> Error in map(.x, .f, ...): object 'gto_norm' not found
true_votes <- gto_2012 %>%
dplyr::select(casilla_id, pri_pvem:otros) %>%
gather(party, votes, -casilla_id) %>%
group_by(party) %>%
summarise(total_votes = sum(votes)) %>%
mutate(party = factor(party, levels = levels(norm_votes$party)))
#> Error in eval(lhs, parent, parent): object 'gto_2012' not found
ggplot(norm_votes, aes(x = votes)) +
geom_histogram(binwidth = 1000, alpha = 0.7) +
facet_wrap(~party, scales = "free_x") +
geom_vline(data = true_votes, aes(xintercept = total_votes),
color = "red") +
labs(title = "PP Modelo normal: total de votos",
x = expression(y[rep]), y = "")
#> Error in ggplot(norm_votes, aes(x = votes)): object 'norm_votes' not foundExaminamos otro nivel de desagregación: las distribuciones predictivas posteriores para el total de votos por estrato, mostramos las gráficas para 3 estratos.


Modelo con distribución mezcla
Tras analizar las simulaciones de la distribución predictiva posterior notamos que el modelo Normal no ajustaba a los partidos chicos, observamos que para estos había muchas casillas con cero votos y unas cuantas con muchos votos. Adicionalmente notamos que la distribución t ajustaba mejor que la normal gracias a que tiene colas más pesadas. Ante esto propusimos un modelo mezcla donde para la \(k\) es casilla el número de votos observados es cero con probabilidad \(p_k\) y sigue una distribución \(t\) con probabilidad \((1-p_k)\):
- Nivel 1
\[X_k\sim p_k\mathsf{\delta}_0(x)+(1-p_k)\mathsf{t}(n_k\theta_k,n_k^{-1}\tau_k^{\text{distrito}},\nu_k^{\text{distrito}}) \mathcal{I}_{[0,750]},\]
\[\begin{align} \theta_k= \text{logit}^{-1} & ( \beta^0 +\beta^{\text{rural}} \cdot \text{rural}_k +\beta^{\text{rural-tamañoM}} \cdot \text{rural}_k \cdot \text{tamañoM}_k \\ +& \beta^{\text{tamañoM}} \cdot \text{tamañoM}_k +\beta^{\text{tamañoL}} \cdot \text{tamañoL}_k +\beta^{\text{distrito}}_{\text{distrito}(k)} \\ +& \beta^{\text{tipoSP}}\cdot \text{tipoSP}_k ), \end{align}\]
\[\begin{align} p_k = \text{logit}^{-1} & ( \beta^0_p +\beta_p^{\text{rural}} \cdot \text{rural}_k +\beta_p^{\text{rural-tamañoM}} \cdot \text{rural}_k \cdot \text{tamañoM}_k \\ +& \beta_p^{\text{tamañoM}} \cdot \text{tamañoM}_k +\beta_p^{\text{tamañoL}} \cdot \text{tamañoL}_k +\beta^{\text{distrito-p}}_{\text{distrito}(k)} \\ +& \beta_p^{\text{tipoSP}}\cdot \text{tipoSP}_k ). \end{align}\]
- Nivel 2
\[\begin{align} \beta^{\text{distrito}}_{j}\sim \mathsf{N}\left(\mu^{\text{distrito}}, \sigma_{\text{distrito}}^2\right). \end{align}\]
\[\begin{align} \beta^{\text{distrito-p}}_{j}\sim \mathsf{N}\left(\mu^{\text{distrito-p}}, \sigma_{\text{distrito-p}}^2\right). \end{align}\]
El código en JAGS:
eval(parse(text = deparse(quickcountmx:::model_norm)[3]))#> Warning in gzfile(file, "rb"): cannot open compressed file 'cache_manual/
#> model_string_bern_t.rds', probable reason 'No such file or directory'
#> Error in gzfile(file, "rb"): cannot open the connectionmodel_string %>% cat()
#> Error in eval(lhs, parent, parent): object 'model_string' not foundLo ajustamos llamando nuevamente a la función mrp_party_estimation(), si no
especificamos el parámetro model_string ajusta por defecto el modelo mezcla.
gto_mixture <- mrp_estimation(gto_2012, ... = pri_pvem:otros,
stratum = distrito_loc_17, frac = 0.06, n_iter = 3000, n_burnin = 2000,
n_chains = 2, seed = 19291, parallel = TRUE, n_cores = 6)#> Warning in gzfile(file, "rb"): cannot open compressed file 'cache_manual/
#> gto_mixture.rds', probable reason 'No such file or directory'
#> Error in gzfile(file, "rb"): cannot open the connectionEvaluación de ajuste
Repetimos las gráficas de la distribución predictiva posterior del total de votos para el PAN (partido ganador) y para Movimiento Ciudadano (partido chico).
mixture_votes <- map_df(gto_norm$jags_fits,
~apply(.$BUGSoutput$sims.list$x, 1, sum)) %>%
mutate(n_sim = 1:n()) %>%
gather(party, votes, -n_sim)
#> Error in map(.x, .f, ...): object 'gto_norm' not found
ggplot(mixture_votes, aes(x = votes)) +
geom_histogram(binwidth = 1000, alpha = 0.7) +
facet_wrap(~party, scales = "free_x") +
geom_vline(data = true_votes, aes(xintercept = total_votes),
color = "red") +
labs(title = "PP Modelo normal: total de votos",
x = expression(y[rep]), y = "")
#> Error in ggplot(mixture_votes, aes(x = votes)): object 'mixture_votes' not foundMostramos también las gráficas para los mismos 3 estratos que en el caso normal.


Calibración
Para evaluar el modelo complementamos con pruebas de calibración, siguiendo los siguientes pasos:
Simulamos \(n\) muestras.
Para cada muestra creamos intervalos de 95%.
Revisamos el porcentaje de intervalos que contienen el valor observado.
Simulamos bajo los siguientes escenarios:
Muestras completas.
Censuramos las muestras completas usando patrones observados de la llegada de datos de cada distrito y ámbito (rural/urbano).
Censuramos las muestras completas eliminando estratos.
Estimador de razón
Comparamos el desempeño del modelo a lo largo de las muestras simuladas con el estimador de razón combinado:
\[\hat{p_k}=\frac{\hat{X_k}}{\hat{Y}}=\frac{\sum_h \hat{X_{kh}}}{\sum_h \hat{Y_{h}}}=\frac{\sum_h \frac{N_h}{n_h} \sum_i X_{khi}}{\sum_h \frac{N_h}{n_h} \sum_i Y_{hi}}\]
Utilizamos bootstrap para estimar los errores estándar. Notar que en el caso de estratos faltantes se debe seleccionar una estrategia para utilizar este estimador, pues como tal no esta definido si faltan estratos.
10.11.0.1.1 Gráficas de calibración
En las siguientes gráficas el alto de las barras representa la longitud media de la presición (2 veces el error estándar), y el número indica el porcentaje de intervalos (de 95% de confianza/probabilidad) que cubrieron el verdadero valor.

Elección Guanajuato 2018
Se reportaron los intervalos de probabilidad de las 9:45 pm, con 357 casillas.

Implementación
Implementamos en JAGS, la estimación se puede consultar y reproducir completamente con el paquete de R quickcountmx (Ortiz 2018).
La reproducibilidad es crucial para examinar la veracidad de las conclusiones de un trabajo científico.
La reproducibilidad ayuda a lograr la transparencia en el procedimiento electoral, fomenta la confianza en las instituciones y da legitimidad al resultado del conteo rápido.
Modelo nacional
El modelo multinivel con distribución de probabilidad mezcla resulta muy lento para la elección nacional, por lo que se tomaron las siguientes medidas:
División de datos: Se estima un modelo de forma independiente para cada una de 7 regiones geográficas lo que nos permite paralelizar por región y por candidato, la desventaja es que no podemos usar información entre las regiones.
Se modela utilizando una distribucióin binomial negativa (un parámetro menos).
Se implementó con Stan en lugar de JAGS (el código está en el paquete de R quickcountmx).
Más detalles del modelo aquí.
Referencias
Albert, J. 2009. Bayesian Computation with R. Use R! Springer New York. https://books.google.com.mx/books?id=AALhk\_mt7SYC.
Gelman, Andrew, and Jennifer Hill. 2007. Data Analysis Using Regression and Multilevel/Hierarchical Models. Vol. Analytical methods for social research. New York: Cambridge University Press.
Mendoza, Manuel, and Luis E. Nieto-Barajas. 2016. “Quick Counts in the Mexican Presidential Elections: A Bayesian Approach.” Electoral Studies 43 (C):124–32. https://doi.org/10.1016/j.electstud.2016.06.007.
Lehtonen, Risto. 2012. “Calibrated Bayes, an Alternative Inferential Paradigm for Official Statistics: Discussion.” Journal of Official Statistics 28 (3). SCB:353–57.
Park, David K., Andrew Gelman, and Joseph Bafumi. 2004. “Bayesian Multilevel Estimation with Poststratification: State-Level Estimates from National Polls.” Political Analysis 12 (04):375–85. https://EconPapers.repec.org/RePEc:cup:polals:v:12:y:2004:i:04:p:375-385_00.