10.8 JAGS
JAGS (Just Another Gibbs Sampler), WinBUGS y
OpenBUGS son programas que
implementan métodos MCMC para generar simulaciones de distribuciones
posteriores. Los paquetes rjags y R2jags permiten ajustar modelos en JAGS
desde R. Es muy fácil utilizar estos programas pues uno simplemente debe
especificar las distribuciones iniciales, la verosimilitud y los datos
observados.
Especificación del modelo
Repitamos el caso del sesgo de la modela usando JAGS. Vale la pena realizar un diagrama.

El diagrama captura las dependencias entre los datos y los parámetros y veremos que puede facilitar la implementación en JAGS pues cada flecha en el diagrama corresponde a una línea de código en la especificación del modelo.
modelo_bb.bugs <-
'
model{
for(i in 1:N){
x[i] ~ dbern(theta)
}
# inicial
theta ~ dbeta(1, 1)
}
'el ciclo for indica que cada dato observado \(x_i\) proviene de una distribución Bernoulli con parámetro \(\theta\). Afuera del ciclo escribimos las distribución inicial, \(\theta \sim Beta(1, 1)\).
Inicializar cadenas
El modelo ya esta especificado, pero aún debemos indicar los valores de las variables en el modelo, para esto definimos los valores en R y después los mandamos a JAGS.
Falta especificar el valor inicial de \(\theta\), JAGS tiene una manera de hacerlo automaticamente, pero muchas veces vale la pena tener control de los valores iniciales. En ocasiones la eficiencia del proceso puede incrementar si seleccionamos valores iniciales razonables. Kruschke sugiere utilizar como puntos iniciales los estimadores de máxima verosimilitud, esto es porque usualmente la distribución posterior no esta muy lejana de la función de verosimilitud. En este caso el estimador de máxima verosimilitud para \(\theta\) es \(\hat{\theta}=z/N\).
theta_init <- sum(x) / NEsta manera de especificar los valores iniciales no siempre se recomienda pues cuando queremos evaluar la convergencia de la cadena muchas veces se sugiere correr varias cadenas con puntos iniciales muy dispersos a lo largo del espacio de parámetros, de tal manera que cuando las cadenas convergen se pueda determinar que la etapa de calentamiento a terminado. Un punto medio es iniciar las cadenas en un punto aleatorio cercano al estimador de máxima verosimilitud.
init_theta <- function(){
x_s <- sample(x, replace = TRUE)
return(list(theta = sum(x_s) / N))
}Generar las cadenas
Ahora llamamos a JAGS y generamos las cadenas. Para esto usaremos el paquete
R2jags, otro paquete para llamar JAGS desde R es rjags.
library(R2jags)
#> Loading required package: rjags
#> Linked to JAGS 4.3.0
#> Loaded modules: basemod,bugs
#>
#> Attaching package: 'R2jags'
#> The following object is masked from 'package:coda':
#>
#> traceplot
cat(modelo_bb.bugs, file = 'modelo_bb.bugs')
jags_fit <- jags(
model.file = "modelo_bb.bugs", # modelo de JAGS
inits = init_theta, # valores iniciales
data = list(x = x, N = N), # lista con los datos
parameters.to.save = c("theta"), # parámetros por guardar
n.chains = 1, # número de cadenas
n.iter = 1000, # número de pasos
n.burnin = 500 # calentamiento de la cadena
)
#> module glm loaded
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 14
#> Unobserved stochastic nodes: 1
#> Total graph size: 17
#>
#> Initializing model
# plot(jags_fit)Podemos ver un resumen del ajuste:
head(jags_fit$BUGSoutput$summary)
#> mean sd 2.5% 25% 50% 75% 97.5%
#> deviance 15.467 1.222 14.549 14.630 15.025 15.744 19.091
#> theta 0.754 0.106 0.522 0.685 0.768 0.832 0.913Y graficar la cadena:
traceplot(jags_fit, varname = "theta")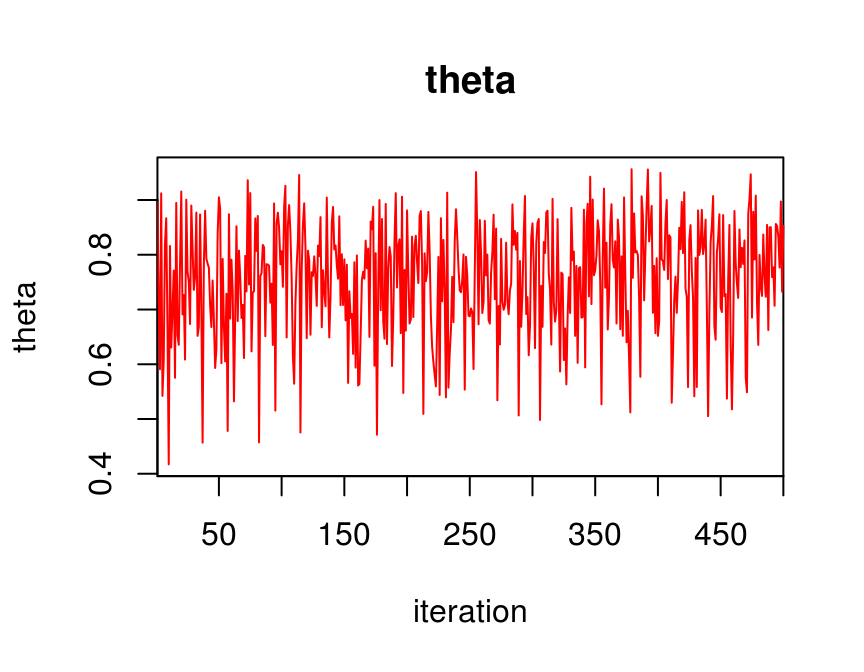
Ejemplo normal
Recordemos el ejemplo normal con media y varianza desconocidas. ¿Cuál es el modelo gráfico asociado?
N <- 50 # Observamos 20 realizaciones
set.seed(122)
x <- rnorm(N, 2, 2)
modelo_normal.bugs <-
'
model{
for(i in 1:N){
x[i] ~ dnorm(mu, nu)
}
# iniciales
nu ~ dgamma(3, 3)
sigma2 <- 1 / nu
mu ~ dnorm(1.5, 1 / 16)
}
'el ciclo for indica que cada dato observado \(x_i\) proviene de una distribución
Normal con media \(\mu\) y varinza \(1 / \nu\) (precisión \(\nu\)). Afuera del ciclo
escribimos las distribuciones iniciales, \(\nu \sim Gamma(3, 3)\), esto es
\(\sigma^2 \sim GI(3, 3)\) y \(\mu\) se distribuye Normal con media \(\mu = 1.5\) y
varianza \(\tau^2 = 16\).
El modelo ya esta especificado, pero aun falta indicar los valores de las variables en el modelo, para esto definimos los valores en R y después los mandamos a JAGS.
library(R2jags)
cat(modelo_normal.bugs, file = 'modelo_normal.bugs')
# valores iniciales para los parámetros, si no se especifican la función jags
# generará valores iniciales
jags_inits <- function(){
list(mu = rnorm(1, mean(x), 5), nu = 1 / runif(1, 2, 4))
}
jags_fit <- jags(
model.file = "modelo_normal.bugs", # modelo de JAGS
inits = jags_inits, # valores iniciales
data = list(x = x, N = N), # lista con los datos
parameters.to.save = c("mu", "sigma2"), # parámetros por guardar
n.chains = 1, # número de cadenas
n.iter = 10000, # número de pasos
n.burnin = 1000, # calentamiento de la cadena
n.thin = 1
)
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 50
#> Unobserved stochastic nodes: 2
#> Total graph size: 59
#>
#> Initializing model
jags_fit
#> Inference for Bugs model at "modelo_normal.bugs", fit using jags,
#> 1 chains, each with 10000 iterations (first 1000 discarded)
#> n.sims = 9000 iterations saved
#> mu.vect sd.vect 2.5% 25% 50% 75% 97.5%
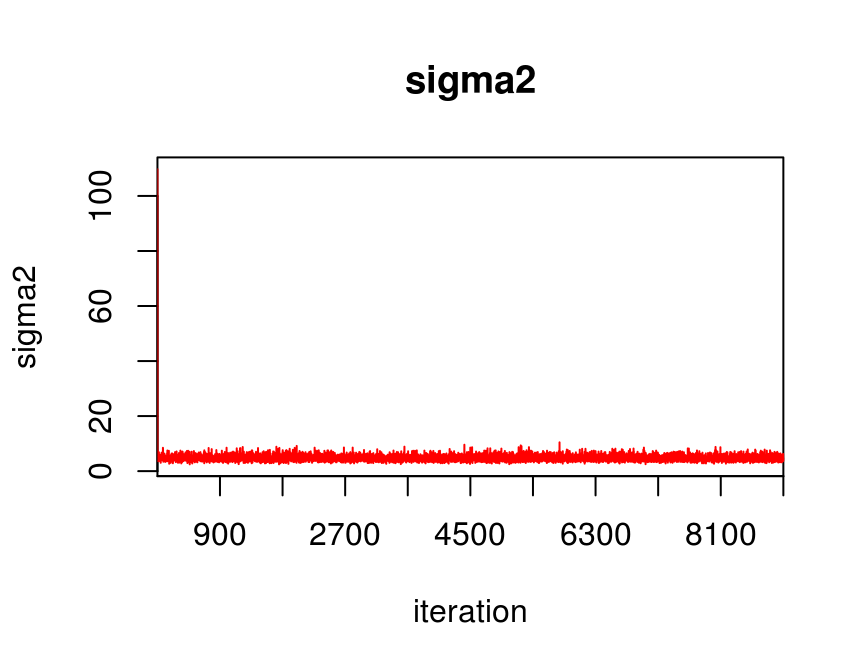
#> mu 1.91 0.313 1.31 1.70 1.91 2.12 2.53
#> sigma2 4.75 1.449 3.25 4.07 4.62 5.28 6.91
#> deviance 223.50 2.388 221.46 222.00 222.82 224.27 229.28
#>
#> DIC info (using the rule, pD = var(deviance)/2)
#> pD = 2.9 and DIC = 226.3
#> DIC is an estimate of expected predictive error (lower deviance is better).
# podemos ver las cadenas
traceplot(jags_fit, varname = c("mu", "sigma2"))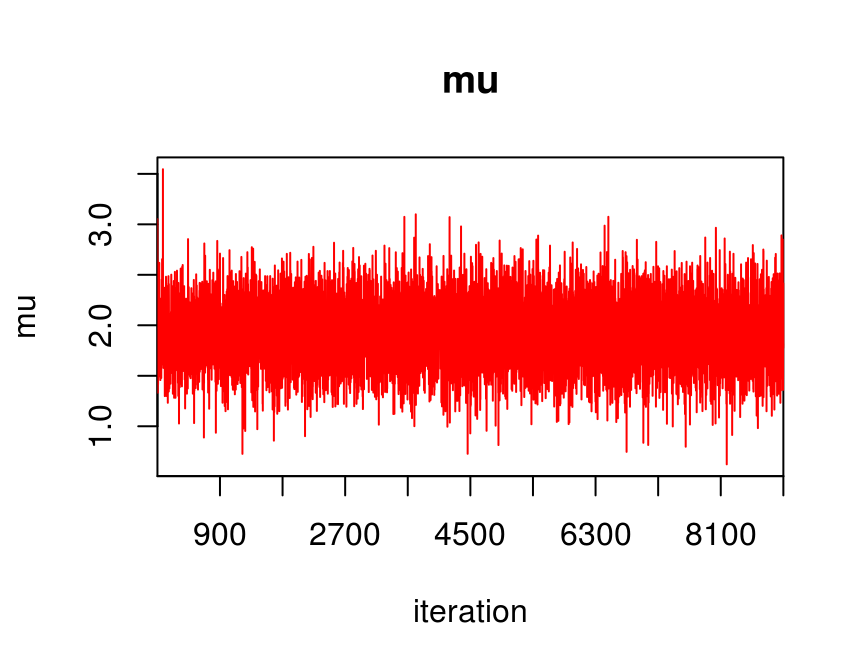
 Realiza un histograma de la distribución
predictiva. Construye un intervalo de \(95\%\) de probabilidad para la predicción.
Pista: utiliza
Realiza un histograma de la distribución
predictiva. Construye un intervalo de \(95\%\) de probabilidad para la predicción.
Pista: utiliza jags_fit$BUGSoutput$sims.matrix.
jags_fit <- jags(
model.file = "modelo_normal.bugs", # modelo de JAGS
inits = list(jags_inits()), # valores iniciales
data = list(x = c(NA, x), N = N + 1), # lista con los datos
parameters.to.save = c("mu", "sigma2", "x"), # parámetros por guardar
n.chains = 1, # número de cadenas
n.iter = 10000, # número de pasos
n.burnin = 1000, # calentamiento de la cadena
n.thin = 1
)
#> Compiling model graph
#> Resolving undeclared variables
#> Allocating nodes
#> Graph information:
#> Observed stochastic nodes: 50
#> Unobserved stochastic nodes: 3
#> Total graph size: 60
#>
#> Initializing model
head(jags_fit$BUGSoutput$summary)
#> mean sd 2.5% 25% 50% 75% 97.5%
#> deviance 223.420 1.988 221.456 221.991 222.823 224.223 228.713
#> mu 1.908 0.305 1.309 1.705 1.906 2.109 2.508
#> sigma2 4.740 0.945 3.285 4.066 4.611 5.274 6.939
#> x[1] 1.918 2.213 -2.392 0.438 1.924 3.393 6.268
#> x[2] 4.621 0.000 4.621 4.621 4.621 4.621 4.621
#> x[3] 0.248 0.000 0.248 0.248 0.248 0.248 0.248
mus <- jags_fit$BUGSoutput$sims.matrix[, "mu"]
sigmas <- sqrt(jags_fit$BUGSoutput$sims.matrix[, "sigma2"])
y <- rnorm(length(mus), mus, sigmas)
mean(y)
#> [1] 1.88
sd(y)
#> [1] 2.21